

Cómo instalar y configurar Apache Hadoop en un solo nodo en CentOS 7

- 4787
- 302
- Carmen Casillas
Apache Hadoop es una compilación de marco de código abierto para los datos distribuidos de almacenamiento y procesamiento de big data a través de grupos de computadora. El proyecto se basa en los siguientes componentes:
- Hadoop común - Contiene las bibliotecas y utilidades de Java que necesitan otros módulos Hadoop.
- HDFS - Sistema de archivos distribuido Hadoop: un sistema de archivos escalable basado en Java distribuido en múltiples nodos.
- Mapa reducido - Marco de hilo para procesamiento paralelo de big data.
- Hilo de hadoop: Un marco para la gestión de recursos de clúster.
Instalar Hadoop en Centos 7 Este artículo lo guiará sobre cómo puede instalar Apache Hadoop en un solo clúster de nodo en Centos 7 (También funciona para Rhel 7 y Fedora 23+ versiones). Este tipo de configuración también se hace referencia como Modo pseudop-distribuido de Hadoop.
Paso 1: Instale Java en Centos 7
1. Antes de continuar con la instalación de Java, primero inicie sesión con el usuario root o un usuario con los privilegios raíz configurar su nombre de host de máquina con el siguiente comando.
# hostnamectl set-hostname maestro
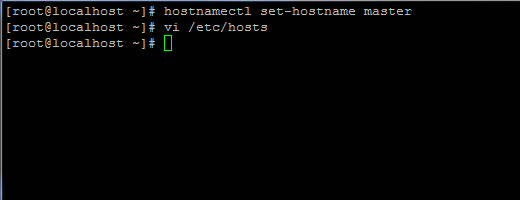 Establecer nombre de host en Centos 7
Establecer nombre de host en Centos 7 Además, agregue un nuevo registro en el archivo hosts con su propia máquina FQDN para señalar la dirección IP de su sistema.
# vi /etc /huéspedes
Agregue la línea a continuación:
192.168.1.41 maestro.hadoop.lan
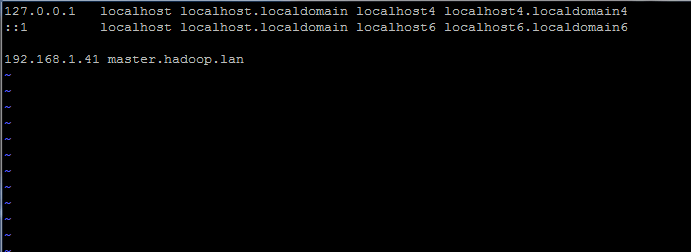 Establecer el nombre del nombre de host en /etc /hosts
Establecer el nombre del nombre de host en /etc /hosts Reemplace el nombre de host anterior y los registros de FQDN con su propia configuración.
2. A continuación, vaya a la página de descarga de Oracle Java y tome la última versión de Kit de desarrollo de Java SE 8 en su sistema con la ayuda de rizo dominio:
# curl -lo -h "cookie: oraclelicense = Aceptación -SecureBackup -Cookie" "http: // Descargar.oráculo.com/otn-pub/java/jdk/8u92-b14/jdk-8u92-linux-x64.RPM "
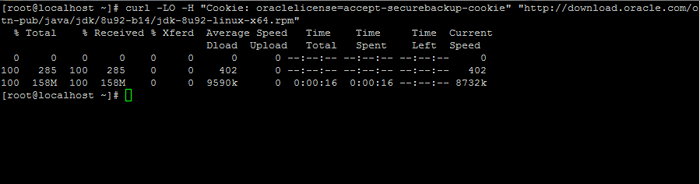 Descargar Java SE Development Kit 8
Descargar Java SE Development Kit 8 3. Después de que termine la descarga binaria de Java, instale el paquete emitiendo el siguiente comando:
# RPM -UVH JDK-8U92-LINUX-X64.rpm
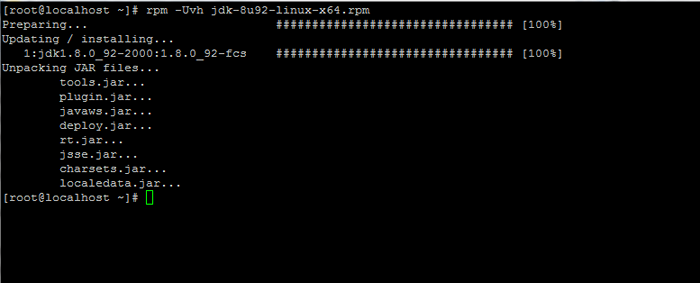 Instale Java en Centos 7
Instale Java en Centos 7 Paso 2: Instale el marco Hadoop en Centos 7
4. A continuación, cree una nueva cuenta de usuario en su sistema sin poderes raíz que la usaremos para la ruta de instalación y el entorno de trabajo de Hadoop. El nuevo directorio de hogar de la cuenta residirá en /OPT/Hadoop directorio.
# userAdd -d /opt /hadoop hadoop # passwd hadoop
5. En el siguiente paso, visite la página Apache Hadoop para obtener el enlace para la última versión estable y descargue el archivo en su sistema.
# curl -o http: // apache.javapipea.com/hadoop/común/hadoop-2.7.2/Hadoop-2.7.2.alquitrán.GZ
 Descargar paquete Hadoop
Descargar paquete Hadoop 6. Extraiga el archivo de la copia del contenido del directorio a la ruta de inicio de la cuenta de Hadoop. Además, asegúrese de cambiar los permisos de archivos copiados en consecuencia.
# tar xfz hadoop-2.7.2.alquitrán.GZ # CP -RF Hadoop -2.7.2/*/opt/hadoop/ # chown -r hadoop: hadoop/opt/hadoop/
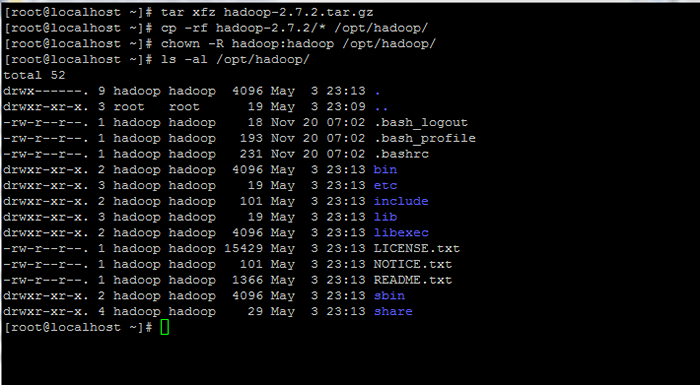 Extractar y establecer permisos en Hadoop
Extractar y establecer permisos en Hadoop 7. A continuación, inicie sesión con hadoop usuario y configurar Hadoop y Variables de entorno Java en su sistema editando el .bash_profile archivo.
# SU - Hadoop $ VI .bash_profile
Agregue las siguientes líneas al final del archivo:
## variables de envía de Java Exportar java_home =/usr/java/predeterminado exportación ruta = $ ruta: $ java_home/bin exports classpath =.: $ Java_home/jre/lib: $ java_home/lib: $ java_home/lib/herramientas.frasco ## variables de env envado Exportar hadoop_home =/opt/hadoop Exportar hadoop_common_home = $ hadoop_home exportoop_hdfs_home = $ hadoop_home export hadoop_mapred_home = $ hadoop_home exportoop_yarn_home = $ hadoop_home exportoop_opts = "-djava.biblioteca.ruta = $ hadoop_home/lib/native "exportoop_common_lib_native_dir = $ hadoop_home/lib/native export ruta = $ ruta: $ hadoop_home/sbin: $ hadoop_home/bin
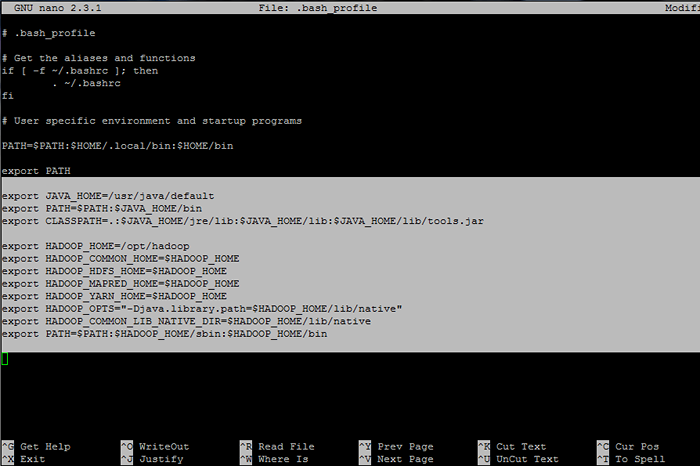 Configurar variables de entorno Hadoop y Java
Configurar variables de entorno Hadoop y Java 8. Ahora, inicialice las variables de entorno y verifique su estado emitiendo los siguientes comandos:
$ fuente .bash_profile $ echo $ hadoop_home $ echo $ java_home
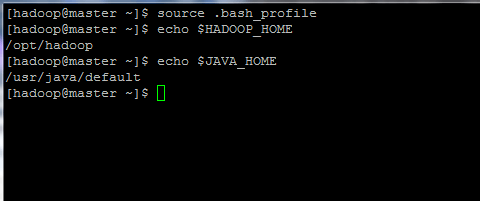 Inicializar las variables de entorno de Linux
Inicializar las variables de entorno de Linux 9. Finalmente, configure la autenticación basada en la tecla SSH para hadoop cuenta ejecutando los siguientes comandos (reemplace el nombre de host o FQDN en contra de SSH-Copy-ID comando en consecuencia).
Además, deja el frase Archivado en blanco para iniciar sesión automáticamente a través de SSH.
$ ssh-keygen -t rsa $ ssh-copy-id maestro.hadoop.lan
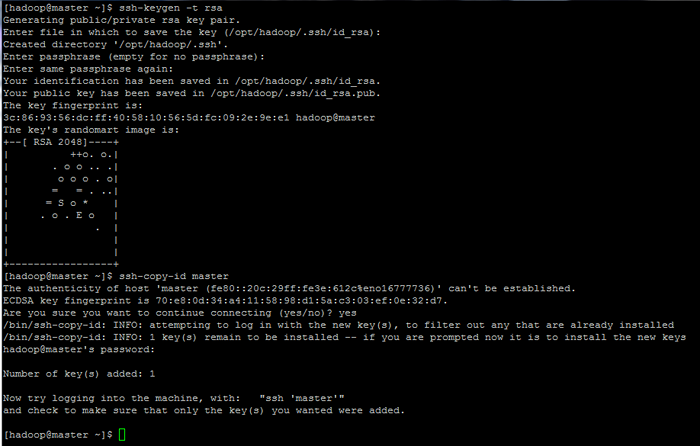 Configurar páginas de autenticación basadas en la tecla SSH: 1 2 3
Configurar páginas de autenticación basadas en la tecla SSH: 1 2 3
- « Encuentre las 10 direcciones IP principales que acceden a su servidor web Apache
- 10 preguntas útiles de la entrevista sobre servicios de Linux y Daemons »