

Cómo instalar y configurar Hadoop en CentOS/RHEL 8

- 1473
- 19
- Claudia Baca
Hadoop es un marco de software gratuito, de código abierto y basado en Java utilizado para el almacenamiento y procesamiento de grandes conjuntos de datos en grupos de máquinas. Utiliza HDFS para almacenar sus datos y procesar estos datos utilizando MapReduce. Es un ecosistema de herramientas de big data que se utilizan principalmente para la minería de datos y el aprendizaje automático. Tiene cuatro componentes principales, como Hadoop Common, HDFS, Yarn y MapReduce.
En esta guía, explicaremos cómo instalar Apache Hadoop en Rhel/Centos 8.
Paso 1 - Desactivar Selinux
Antes de comenzar, es una buena idea deshabilitar el selinux en su sistema.
Para deshabilitar Selinux, abra el archivo/etc/selinux/config:
nano/etc/selinux/config
Cambie la siguiente línea:
Selinux = discapacitado
Guarde el archivo cuando haya terminado. A continuación, reinicie su sistema para aplicar los cambios de Selinux.
Paso 2 - Instale Java
Hadoop está escrito en Java y solo admite Java versión 8. Puede instalar OpenJDK 8 y Ant usando el comando DNF como se muestra a continuación:
DNF Instalar Java-1.8.0 -Openjdk Ant -y
Una vez instalado, verifique la versión instalada de Java con el siguiente comando:
Java -versión
Debe obtener la siguiente salida:
OpenJDK versión "1.8.0_232 "OpenJDK Runtime Entorny (Build 1.8.0_232-B09) OpenJDK de 64 bits VM (compilación 25.232-B09, modo mixto)
Paso 3: crea un usuario de Hadoop
Es una buena idea crear un usuario separado para ejecutar Hadoop por razones de seguridad.
Ejecute el siguiente comando para crear un nuevo usuario con el nombre Hadoop:
UserAdd Hadoop
A continuación, configure la contraseña de este usuario con el siguiente comando:
passwd hadoop
Proporcionar y confirmar la nueva contraseña como se muestra a continuación:
Cambiar contraseña para el usuario Hadoop. Nueva contraseña: repetir nueva contraseña: passwd: todos los tokens de autenticación actualizados correctamente.
Paso 4 - Configurar la autenticación basada en la tecla SSH
A continuación, deberá configurar la autenticación SSH sin contraseña para el sistema local.
Primero, cambie al usuario a Hadoop con el siguiente comando:
Su - Hadoop
A continuación, ejecute el siguiente comando para generar pares de claves públicas y privadas:
ssh -keygen -t RSA
Se le pedirá que ingrese el nombre de archivo. Simplemente presione Entrar para completar el proceso:
Generación de pares de claves RSA públicas/privadas. Ingrese el archivo en el que guardar la clave (/home/hadoop/.ssh/id_rsa): directorio creado '/home/hadoop/.ssh '. Ingrese la frase de pases (vacío sin frase de pases): ingrese la misma frase de pases nuevamente: su identificación se ha guardado en/home/hadoop/.ssh/id_rsa. Su clave pública ha sido guardada en/home/hadoop/.ssh/id_rsa.pub. La huella digital clave es: SHA256: A/OG+N3CNBSSYE1ULKKK95GYS0POOC0DVJ+YH1DFZPF8 [ELECCIÓN PROTEGADA] La imagen RandomArt de la clave es:+--- [RSA 2048] ----+| | | | | . | | . O O O | |… O s o o | | O = + O O . | | o * o = b = . | | + O.O.O + + . | | +=*ob.+ O E | +---- [SHA256]-----+
A continuación, agregue las claves públicas generadas de ID_RSA.Pub a autorizado_keys y establecer el permiso adecuado:
gato ~/.ssh/id_rsa.Pub >> ~/.ssh/autorized_keys chmod 640 ~/.ssh/autorized_keys
A continuación, verifique la autenticación SSH sin contraseña con el siguiente comando:
ssh localhost
Se le pedirá que autentique hosts agregando claves RSA a los hosts conocidos. Escriba sí y presione Enter para autenticar el LocalHost:
La autenticidad del host 'localhost (:: 1)' no se puede establecer. La huella digital de la tecla ECDSA es SHA256: 0YR1KDGU44AKG43PHN2GENUZSVRJBBPJAT3BWRDR3MW. ¿Estás seguro de que quieres continuar conectando (sí/no)? Sí Advertencia: agregó permanentemente 'localhost' (ECDSA) a la lista de anfitriones conocidos. Active la consola web con: SystemCTL Enable - -Now Cockpit.Socket Último inicio de sesión: sáb 1 de febrero 02:48:55 2020 [[correo electrónico protegido] ~] $
Paso 5 - Instale Hadoop
Primero, cambie al usuario a Hadoop con el siguiente comando:
Su - Hadoop
A continuación, descargue la última versión de Hadoop usando el comando wget:
wget http: // apachemirror.Wuchna.com/Hadoop/Common/Hadoop-3.2.1/Hadoop-3.2.1.alquitrán.GZ
Una vez descargado, extraiga el archivo descargado:
tar -xvzf hadoop -3.2.1.alquitrán.GZ
A continuación, cambie el nombre del directorio extraído a Hadoop:
MV Hadoop-3.2.1 Hadoop
A continuación, deberá configurar las variables de entorno Hadoop y Java en su sistema.
Abra el ~/.archivo bashrc en su editor de texto favorito:
nano ~/.bashrc
Agregar las siguientes líneas:
Exportar java_home =/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.232.B09-2.El8_1.x86_64/ export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH : $ Hadoop_home/sbin: $ hadoop_home/bin export hadoop_opts = "-djava.biblioteca.ruta = $ hadoop_home/lib/nativo "
Guarde y cierre el archivo. Luego, active las variables de entorno con el siguiente comando:
fuente ~/.bashrc
A continuación, abra el archivo variable de entorno Hadoop:
nano $ hadoop_home/etc/hadoop/hadoop-envv.mierda
Actualice la variable Java_Home según su ruta de instalación de Java:
Exportar java_home =/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.232.B09-2.El8_1.x86_64/
Guarde y cierre el archivo cuando haya terminado.
Paso 6 - Configurar Hadoop
Primero, deberá crear los directorios NameNode y DataNode dentro del Directorio de inicio de Hadoop:
Ejecute el siguiente comando para crear ambos directorios:
mkdir -p ~/hadoopdata/hdfs/namenode mkdir -p ~/hadoopdata/hdfs/datanode
A continuación, edite el sitio de núcleo.xml Archivo y actualización con el nombre de host de su sistema:
nano $ hadoop_home/etc/hadoop/nore-site.xml
Cambie el siguiente nombre según su nombre de host del sistema:
FS.defaultfs hdfs: // hadoop.tecadmin.com: 9000| 123456 | FS.defaultfs hdfs: // hadoop.tecadmin.com: 9000 |
Guarde y cierre el archivo. Entonces, edite el sitio HDFS.xml archivo:
nano $ hadoop_home/etc/hadoop/hdfs-site.xml
Cambie la ruta del directorio NameNode y DataNode como se muestra a continuación:
DFS.Replicación 1 DFS.nombre.Archivo Dir: /// home/hadoop/hadoopdata/hdfs/nameNode DFS.datos.archivo dir: /// home/hadoop/hadoopdata/hdfs/datanode| 1234567891011121314151617 | DFS.Replicación 1 DFS.nombre.Archivo Dir: /// home/hadoop/hadoopdata/hdfs/nameNode DFS.datos.archivo dir: /// home/hadoop/hadoopdata/hdfs/datanode |
Guarde y cierre el archivo. Entonces, edite el sitio de mapred.xml archivo:
nano $ hadoop_home/etc/hadoop/mapred-site.xml
Hacer los siguientes cambios:
Mapa reducido.estructura.hilo de nombre| 123456 | Mapa reducido.estructura.hilo de nombre |
Guarde y cierre el archivo. Entonces, edite el hilo.xml archivo:
nano $ hadoop_home/etc/hadoop/hilo-sitio.xml
Hacer los siguientes cambios:
hilo.nodo.Aux-Services MapReduce_Shuffle| 123456 | hilo.nodo.Aux-Services MapReduce_Shuffle |
Guarde y cierre el archivo cuando haya terminado.
Paso 7 - Inicie Hadoop Cluster
Antes de comenzar el clúster de Hadoop. Deberá formatear el NameNode como usuario de Hadoop.
Ejecute el siguiente comando para formatear el hadoop namenode:
HDFS namenode -Format
Debe obtener la siguiente salida:
2020-02-05 03: 10: 40,380 Información Namenode.NnstorageretententManager: va a retener 1 imágenes con txid> = 0 2020-02-05 03: 10: 40,389 Información Namenode.FSIMAGE: FSIMAGSAVER Clean CheckPoint: TXID = 0 Cuando se encuentra con el cierre. 2020-02-05 03: 10: 40,389 Información Namenode.Namenode: shutdown_msg: /******************************************** ***************** SHUCEDOWN_MSG: apagar NameNode en Hadoop.tecadmin.com/45.58.38.202 ************************************************** ***********/
Después de formar el NameNode, ejecute el siguiente comando para iniciar el clúster Hadoop:
inicio-DFS.mierda
Una vez que el HDFS comenzó con éxito, debe obtener el siguiente resultado:
Comenzando Nanodes en [Hadoop.tecadmin.com] Hadoop.tecadmin.com: Advertencia: agregado permanentemente 'Hadoop.tecadmin.com, Fe80 :: 200: 2DFF: Fe3a: 26CA%eth0 '(ECDSA) a la lista de anfitriones conocidos. Iniciar Datanodes iniciando NameNodes secundarios [Hadoop.tecadmin.com]
A continuación, inicie el servicio de hilo como se muestra a continuación:
start-yarn.mierda
Debe obtener la siguiente salida:
Iniciar ResourceManager inicial Nodemanagers
Ahora puede verificar el estado de todos los servicios de Hadoop utilizando el comando JPS:
JPS
Debería ver todos los servicios en ejecución en la siguiente salida:
7987 DATANODE 9606 JPS 8183 Secondarynamenode 8570 Nodemanager 8445 ResourceManager 7870 Namenode
Paso 8 - Configurar firewall
Hadoop ahora se inicia y escucha en el puerto 9870 y 8088. A continuación, deberá permitir estos puertos a través del firewall.
Ejecute el siguiente comando para permitir conexiones Hadoop a través del firewall:
Firewall-CMD --Permanent --Add-Port = 9870/TCP Firewall-CMD --Permanent --Add-Port = 8088/TCP
A continuación, vuelva a cargar el servicio Firewalld para aplicar los cambios:
Firewall-CMD-Re-Reload
Paso 9 - Acceda a Hadoop Namenode y Administrador de recursos
Para acceder al NameNode, abra su navegador web y visite la URL http: // su servidor-ip: 9870. Deberías ver la siguiente pantalla:
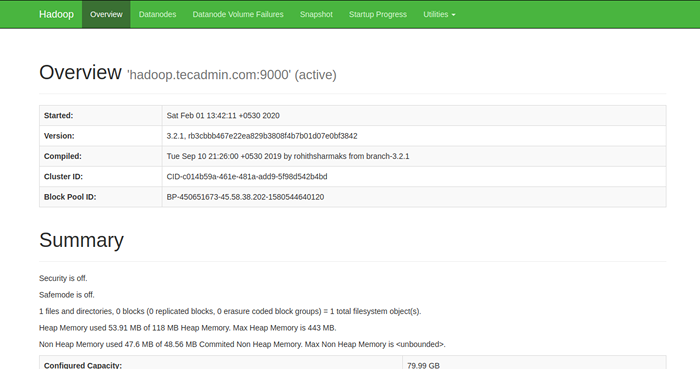
Para acceder a la administración de recursos, abra su navegador web y visite la URL http: // su-server-ip: 8088. Deberías ver la siguiente pantalla:
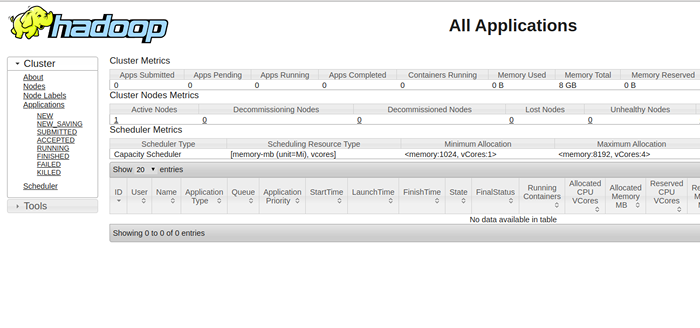
Paso 10 - Verifique el clúster de Hadoop
En este punto, el clúster Hadoop está instalado y configurado. A continuación, crearemos algunos directorios en el sistema de archivos HDFS para probar el Hadoop.
Creemos algún directorio en el sistema de archivos HDFS utilizando el siguiente comando:
HDFS DFS -MKDIR /TEST1 HDFS DFS -MKDIR /TEST2
A continuación, ejecute el siguiente comando para enumerar el directorio anterior:
HDFS DFS -LS /
Debe obtener la siguiente salida:
Encontró 2 elementos DRWXR-XR-X-Hadoop SuperGroup 0 2020-02-05 03:25 /Test1 DRWXR-XR-X-Hadoop SuperGroup 0 2020-02-05 03:35 /Test2
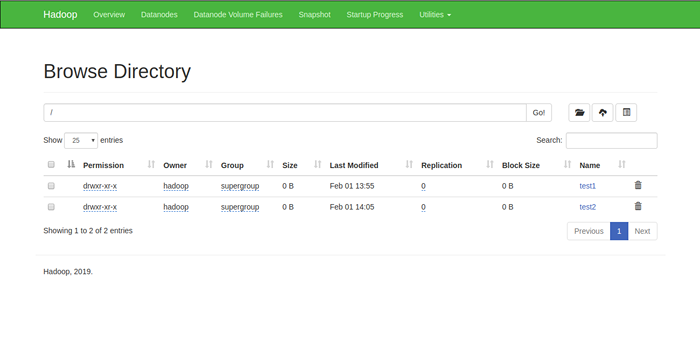
También puede verificar el directorio anterior en la interfaz web Hadoop Namenode.
Vaya a la interfaz web NameNode, haga clic en Utilities => Explorar el sistema de archivos. Debería ver sus directorios que ha creado anteriormente en la siguiente pantalla:
Paso 11 - Stop Hadoop Cluster
También puede detener el servicio Hadoop Namenode and Yarn en cualquier momento ejecutando el parada.mierda y parada.mierda Script como usuario de Hadoop.
Para detener el servicio Hadoop Namenode, ejecute el siguiente comando como usuario de Hadoop:
parada.mierda
Para detener el servicio Hadoop Resource Manager, ejecute el siguiente comando:
parada.mierda
Conclusión
En el tutorial anterior, aprendió a configurar el clúster de nodo único Hadoop en Centos 8. Espero que ahora tengas suficiente conocimiento para instalar Hadoop en el entorno de producción.