

Cómo instalar Hadoop en Rhel 8 / Centos 8 Linux
- 1759
- 203
- Claudia Baca
Apache Hadoop es un marco de código abierto utilizado para el almacenamiento distribuido, así como el procesamiento distribuido de grandes datos en grupos de computadoras que se ejecutan en productos hardwares de productos básicos. Hadoop almacena datos en Hadoop Distributed File System (HDFS) y el procesamiento de estos datos se realiza utilizando MapReduce. Yarn proporciona API para solicitar y asignar recursos en el clúster Hadoop.
El marco Apache Hadoop está compuesto por los siguientes módulos:
- Hadoop común
- Sistema de archivos distribuido Hadoop (HDFS)
- HILO
- Mapa reducido
Este artículo explica cómo instalar Hadoop versión 2 en Rhel 8 o Centos 8. Instalaremos HDFS (NameNode y Datanode), hilo, MapReduce en el clúster de nodo único en el modo Pseudo distribuido que se distribuye en una sola máquina. Cada demonio de Hadoop, como HDFS, hilo, MapReduce, etc. se ejecutará como un proceso Java separado/individual.
En este tutorial aprenderás:
- Cómo agregar usuarios para el entorno Hadoop
- Cómo instalar y configurar el Oracle JDK
- Cómo configurar SSH sin contraseña
- Cómo instalar Hadoop y configurar los archivos XML relacionados necesarios
- Cómo comenzar el clúster de Hadoop
- Cómo acceder a la interfaz de usuario web de NameNode y ResourceManager
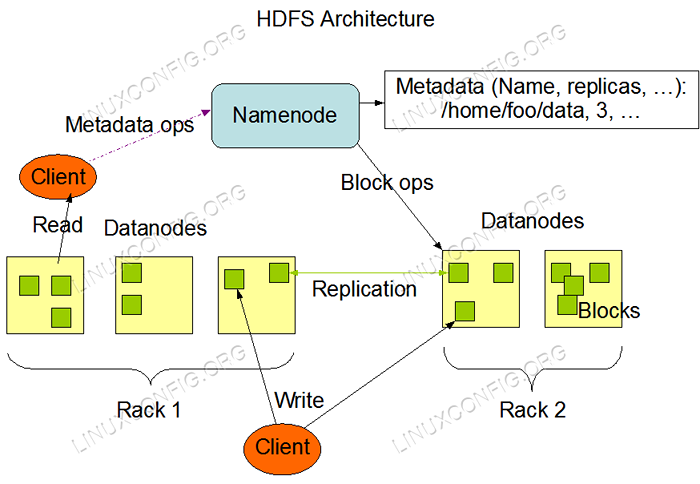
Arquitectura HDFS. Requisitos y convenciones de software utilizados
| Categoría | Requisitos, convenciones o versión de software utilizada |
|---|---|
| Sistema | RHEL 8 / CENTOS 8 |
| Software | Hadoop 2.8.5, Oracle JDK 1.8 |
| Otro | Acceso privilegiado a su sistema Linux como root o a través del sudo dominio. |
| Convenciones | # - requiere que los comandos de Linux dados se ejecuten con privilegios raíz directamente como un usuario raíz o mediante el uso de sudo dominiops - Requiere que los comandos de Linux dados se ejecuten como un usuario regular no privilegiado |
Agregar usuarios para el entorno Hadoop
Cree el nuevo usuario y el grupo usando el comando:
# UserAdd Hadoop # passwd hadoop
[root@hadoop ~]# userAdd hadoop [root@hadoop ~]# passwd hadoop cambiando contraseña para el usuario Hadoop. Nueva contraseña: repetir nueva contraseña: passwd: todos los tokens de autenticación actualizados correctamente. [root@hadoop ~]# cat /etc /passwd | Grep Hadoop Hadoop: X: 1000: 1000 ::/Home/Hadoop:/bin/Bash
Instale y configure el Oracle JDK
Descargue e instale el JDK-8U202-Linux-X64.Paquete oficial de RPM para instalar el Oracle JDK.
[root@hadoop ~]# rpm -ivh jdk-8u202-linux-x64.Advertencia de RPM: JDK-8U202-Linux-X64.RPM: Encabezado V3 RSA/SHA256 Firma, ID clave EC551F03: Nokey Verificación ... ############################## [ 100%] Preparación ... ############################### [100%] Actualización / instalación ... 1: JDK1.8-2000: 1.8.0_202-FCS ################################ [100%] Desempacando archivos jar ... herramientas.Jar ... complemento.Jar ... Javaws.jar ... desplegar.Jar ... RT.Jar ... JSSE.Jar ... Charsets.Jar ... Localedata.frasco…
Después de la instalación para verificar que el Java se haya configurado correctamente, ejecute los siguientes comandos:
[root@hadoop ~]# java -version java versión "1.8.0_202 "Java (TM) SE Runtime Environment (Build 1.8.0_202-B08) Java Hotspot (TM) VM de 64 bits (Build 25.202-B08, modo mixto) [root@hadoop ~]# update-alternativo--config java hay 1 programa que proporciona 'java'. Comando de selección ----------------------------------------------- * + 1/usr/java/jdk1.8.0_202-amd64/jre/bin/java
Configurar ssh sin contraseña
Instale el servidor SSH abierto y abra el cliente SSH o si ya está instalado, enumerará los paquetes siguientes.
[root@hadoop ~]# rpm -qa | Grep OpenSsh* OpenSsh-Server-7.8p1-3.El8.x86_64 OpenSSL-LIBS-1.1.1-6.El8.x86_64 OpenSSL-1.1.1-6.El8.x86_64 OpenSSH-Client-7.8p1-3.El8.x86_64 OpenSSH-7.8p1-3.El8.x86_64 OpenSSL-PKCS11-0.4.8-2.El8.x86_64
Genere pares de claves públicas y privadas con el siguiente comando. El terminal solicitará ingresar el nombre del archivo. Prensa INGRESAR y continuar. Después de eso, copie el formulario de claves públicas ID_RSA.pub a autorizado_keys.
$ ssh -keygen -t rsa $ cat ~/.ssh/id_rsa.Pub >> ~/.ssh/autorized_keys $ chmod 640 ~/.ssh/autorized_keys
[hadoop@hadoop ~] $ ssh -keygen -t rsa generando par de claves RSA pública/privada. Ingrese el archivo en el que guardar la clave (/home/hadoop/.ssh/id_rsa): directorio creado '/home/hadoop/.ssh '. Ingrese la frase de pases (vacío sin frase de pases): ingrese la misma frase de pases nuevamente: su identificación se ha guardado en/home/hadoop/.ssh/id_rsa. Su clave pública ha sido guardada en/home/hadoop/.ssh/id_rsa.pub. La huella digital clave es: SHA256: H+LLPKAJJDD7B0F0JE/NFJRP5/FUEJSWMMZPJFXOELG [email protected] la imagen Randomart de la tecla es: +--- [RSA 2048] ---- +| ... ++*O .o | | O .. +.O.+O.+| | +… * +Oo == | | . O O . mi .OO | | . = .S.* o | | . O.O = O | |… O | | .O. | | O+. | + ---- [SHA256] -----+ [Hadoop@Hadoop ~] $ Cat ~/.ssh/id_rsa.Pub >> ~/.ssh/autorized_keys [hadoop@hadoop ~] $ chmod 640 ~/.ssh/autorized_keys
Verifique la configuración SSH sin contraseña con el comando:
$ ssh
[hadoop@hadoop ~] $ ssh hadoop.salvadera.com consola web: https: // hadoop.salvadera.com: 9090/o https: // 192.168.1.108: 9090/ Último inicio de sesión: sáb 13 de abril 12:09:55 2019 [Hadoop@Hadoop ~] $
Instalar hadoop y configurar archivos XML relacionados
Descargar y extraer Hadoop 2.8.5 del sitio web oficial de Apache.
# wget https: // Archive.apache.org/Dist/Hadoop/Common/Hadoop-2.8.5/Hadoop-2.8.5.alquitrán.gz # tar -xzvf hadoop -2.8.5.alquitrán.GZ
[root@rhel8-sandbox ~]# wget https: // Archive.apache.org/Dist/Hadoop/Common/Hadoop-2.8.5/Hadoop-2.8.5.alquitrán.GZ --2019-04-13 11: 14: 03-- https: // Archivo.apache.org/Dist/Hadoop/Common/Hadoop-2.8.5/Hadoop-2.8.5.alquitrán.GZ Resolviendo Archivo.apache.org (archivo.apache.org) ... 163.172.17.199 Conectando al archivo.apache.org (archivo.apache.org) | 163.172.17.199 |: 443 ... conectado. Solicitud http enviada, en espera de respuesta ... 200 OK Longitud: 246543928 (235m) [Aplicación/X-GZIP] Guardar a: 'Hadoop-2.8.5.alquitrán.GZ 'Hadoop-2.8.5.alquitrán.GZ 100%[================================================= ========================================>] 235.12m 1.47mb/s en 2M 53S 2019-04-13 11:16:57 (1.36 MB/s) - 'Hadoop -2.8.5.alquitrán.GZ 'guardado [246543928/246543928]
Configuración de las variables de entorno
Editar el bashrc Para el usuario de Hadoop a través de la configuración de las siguientes variables de entorno Hadoop:
Exportar hadoop_home =/home/hadoop/hadoop-2.8.5 Export hadoop_install = $ hadoop_home hadoop_mapred_home = $ hadoop_home exportp_common_home = $ hadoop_home exportp_hdfs_home = $ hadoop_home yarn_home = $ hadoop_home exportoop_common_lib_native_dir = $ hadoop_home/lib/bath: hadoop sath: hadoop ° $ hadoop_ = hadoop_ment: hadoop_mat: hadoop_hom/hadoop_home Exportar hadoop_opts = "-djava.biblioteca.ruta = $ hadoop_home/lib/nativo " Fuente el .bashrc En la sesión de inicio de sesión actual.
$ fuente ~/.bashrc
Editar el hadoop-env.mierda archivo que está en /etc/hadoop Dentro del directorio de instalación de Hadoop y realice los siguientes cambios y verifique si desea cambiar cualquier otra configuración.
Exportar java_home = $ java_home:-"/usr/java/jdk1.8.0_202-amd64 " Exportar hadoop_conf_dir = $ hadoop_conf_dir:-"/home/hadoop/hadoop-2.8.5/etc/hadoop " Cambios de configuración en el sitio de núcleo.archivo XML
Editar el sitio de núcleo.xml con vim o puede usar cualquiera de los editores. El archivo está debajo /etc/hadoop adentro hadoop directorio de inicio y agregar entradas siguientes.
FS.defaultfs hdfs: // hadoop.salvadera.com: 9000 hadoop.TMP.prostituta /home/hadoop/hadooptmpdata Además, cree el directorio en hadoop carpeta de inicio.
$ mkdir hadooptmpdata
Cambios de configuración en el sitio HDFS.archivo XML
Editar el sitio HDFS.xml que está presente en la misma ubicación yo.mi /etc/hadoop adentro hadoop directorio de instalación y crear el Namenode/dataNode directorios bajo hadoop directorio de inicio del usuario.
$ mkdir -p hdfs/namenode $ mkdir -p hdfs/datanode
DFS.replicación 1 DFS.nombre.prostituta Archivo: /// home/hadoop/hdfs/namenode DFS.datos.prostituta archivo: /// home/hadoop/hdfs/datanode Cambios de configuración en el sitio de Mapred.archivo XML
Copia el sitio de mapred.xml de sitio de mapred.xml.plantilla usando CP comandar y luego editar el sitio de mapred.xml colocado en /etc/hadoop bajo hadoop Directorio de instilación con los siguientes cambios.
$ cp Mapred-site.xml.plantilla mapred-site.xml
Mapa reducido.estructura.nombre hilo Cambios de configuración en el sitio de hilo.archivo XML
Editar hilo.xml con las siguientes entradas.
mapreduceyarn.nodo.Aux-Servicios mapreduce_shuffle Comenzando el clúster Hadoop
Formatear el NameNode antes de usarlo por primera vez. A medida que el usuario de Hadoop ejecuta el siguiente comando para formatear el Namenode.
$ hdfs namenode -format
[Hadoop@Hadoop ~] $ hdfs namenode -format 19/04/13 11:54:10 Información Namenode.Namenode: startup_msg: /********************************************** ***************** startup_msg: iniciar NameNode startup_msg: user = hadoop startup_msg: host = hadoop.salvadera.com/192.168.1.108 startup_msg: args = [-format] startup_msg: versión = 2.8.5 19/04/13 11:54:17 Información Namenode.FSNamesystem: DFS.namenode.modo seguro.Umbral-PCT = 0.9990000128746033 19/04/13 11:54:17 Información Namenode.FSNamesystem: DFS.namenode.modo seguro.mínimo.DataNodes = 0 19/04/13 11:54:17 Información Namenode.FSNamesystem: DFS.namenode.modo seguro.Extensión = 30000 19/04/13 11:54:18 Información Métricas.Topmetrics: nntop conf: dfs.namenode.arriba.ventana.numer.Buckets = 10 19/04/13 11:54:18 Métricas de información.Topmetrics: nntop conf: dfs.namenode.arriba.numer.usuarios = 10 19/04/13 11:54:18 Métricas de información.Topmetrics: nntop conf: dfs.namenode.arriba.Windows.Actas = 1,5,25 19/04/13 11:54:18 Información Namenode.FSNamesystem: el caché de reintento en Namenode está habilitado 19/04/13 11:54:18 Información Namenode.Fsnamesystem: el caché de reintento usará 0.03 de la entrada total de la entrada de almacenamiento de almacenamiento de almacenamiento y recuperación es 600000 Millis 19/04/13 11:54:18 Información Util.GSET: Capacidad informática para mapas nanoderetrycache 19/04/13 11:54:18 Información Util.GSET: VM Tipo = 64 bit 19/04/13 11:54:18 Información Util.GSET: 0.0299999999329447746% Memoria máxima 966.7 MB = 297.0 KB 19/04/13 11:54:18 Información Util.GSET: Capacidad = 2^15 = 32768 Entradas 19/04/13 11:54:18 Información Namenode.FSIMAGE: nuevo blockpoolid asignado: BP-415167234-192.168.1.108-1555142058167 19/04/13 11:54:18 Información común.Almacenamiento: el directorio de almacenamiento/home/hadoop/hdfs/namenode se ha formateado correctamente. 19/04/13 11:54:18 Información Namenode.FSIMAGEFORMATPROTOBUF: Guardar el archivo de imagen/inicio/hadoop/hdfs/namenode/current/fsimage.CKPT_000000000000000000000 UTILIZANDO NO COMPRESIÓN 19/04/13 11:54:18 Información Namenode.FSIMAGEFORMATPROTOBUF: FILE DE IMAGEN/HOME/HADOOP/HDFS/NAMENODE/Current/FSIMAGE.CKPT_000000000000000000000 de tamaño 323 bytes guardados en 0 segundos. 19/04/13 11:54:18 Información Namenode.NnstorageretentionManager: va a retener 1 imágenes con txid> = 0 19/04/13 11:54:18 Información Util.Exitutil: Salir con el estado 0 19/09/13 11:54:18 Información Namenode.Namenode: shutdown_msg: /******************************************** ***************** SHUCEDOWN_MSG: apagar NameNode en Hadoop.salvadera.com/192.168.1.108 **************************************************** ***********/
Una vez que el NameNode se haya formateado, comience el HDFS usando el inicio-DFS.mierda guion.
$ start-dfs.mierda
[hadoop@hadoop ~] $ start-dfs.SH comenzando nanodes en [Hadoop.salvadera.com] Hadoop.salvadera.com: Comenzar nameNode, registrar a/home/hadoop/hadoop-2.8.5/registros/hadoop-hadoop-nameNode-hadoop.salvadera.comunicarse.Fuera Hadoop.salvadera.com: iniciar datanode, iniciar sesión a/home/hadoop/hadoop-2.8.5/registros/hadoop-hadoop-datanode-hadoop.salvadera.comunicarse.Fuera iniciando NameNodes secundarios [0.0.0.0] La autenticidad del host '0.0.0.0 (0.0.0.0) 'no se puede establecer. La huella digital de la tecla ECDSA es SHA256: E+NFCEK/KVNIGNWDHGFVIKHJBWWGHIJJKFJYGR7NKI. ¿Estás seguro de que quieres continuar conectando (sí/no)? si 0.0.0.0: Advertencia: agregado permanentemente '0.0.0.0 '(ECDSA) a la lista de hosts conocidos. [email protected]ña de 0: 0.0.0.0: Comenzando Secondarynamenode, registrando/home/hadoop/hadoop-2.8.5/registros/hadoop-hadoop-secondarynamenode-hadoop.salvadera.comunicarse.afuera
Para iniciar los servicios de hilo, necesita ejecutar el script de inicio del hilo.mi. start-yarn.mierda
$ start-yarn.mierda
[hadoop@hadoop ~] $ start-yarn.SH iniciando los demonios de hilo que comienza ResourceManager, registrando/home/hadoop/hadoop-2.8.5/registros/hadoop-reseurcemanager-hadoop.salvadera.comunicarse.Fuera Hadoop.salvadera.com: iniciar Nodemanager, registrar a/home/hadoop/hadoop-2.8.5/registros/hadoop-nodemanager-hadoop.salvadera.comunicarse.afuera
Para verificar todos los servicios/demonios de Hadoop se inicia con éxito, puede usar el JPS dominio.
$ JPS 2033 Namenode 2340 Secondarynamenode 2566 ResourceManager 2983 JPS 2139 DataNode 2671 Nodemanager
Ahora podemos verificar la versión actual de Hadoop que puede usar el siguiente comando:
Versión de $ Hadoop
o
Versión de $ HDFS
[hadoop@hadoop ~] $ hadoop versión hadoop 2.8.5 subversión https: // git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8 compilado por JDU en 2018-09-10T03: 32Z compilado con Protoc 2.5.0 desde la fuente con la suma de verificación 9942CA5C745417C14E318835F420733 Este comando se ejecutó usando/home/hadoop/hadoop-2.8.5/Share/Hadoop/Common/Hadoop-Common-2.8.5.jar [hadoop@hadoop ~] $ hdfs versión hadoop 2.8.5 subversión https: // git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8 compilado por JDU en 2018-09-10T03: 32Z compilado con Protoc 2.5.0 desde la fuente con la suma de verificación 9942CA5C745417C14E318835F420733 Este comando se ejecutó usando/home/hadoop/hadoop-2.8.5/Share/Hadoop/Common/Hadoop-Common-2.8.5.jar [hadoop@hadoop ~] $
Interfaz de línea de comandos HDFS
Para acceder a los HDF y crear algunos directorios en la parte superior de DFS, puede usar HDFS CLI.
$ hdfs dfs -mkdir /testData $ hdfs dfs -mkdir /hadoopdata $ hdfs dfs -ls /
[Hadoop@Hadoop ~] $ HDFS DFS -LS / Encontrado 2 elementos DRWXR-XR-X-Hadoop Supergroup 0 2019-04-13 11:58 / HadoopData DRWXR-XR-X-Supergroup Hadoop 0 2019-04-13 11: 59 /TestData
Acceda al NameNode y al hilo desde el navegador
Puede acceder a la interfaz de usuario web para el administrador de recursos de Namenode y el hilo a través de cualquiera de los navegadores como Google Chrome/Mozilla Firefox.
Ui web namenode - http: //: 50070
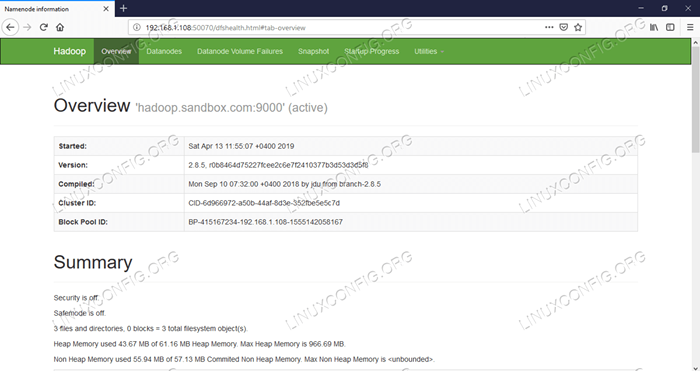 Interfaz de usuario web de NameNode.
Interfaz de usuario web de NameNode. 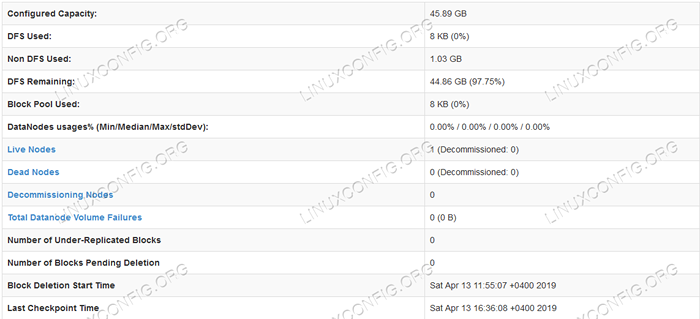 Información detallada de HDFS.
Información detallada de HDFS. 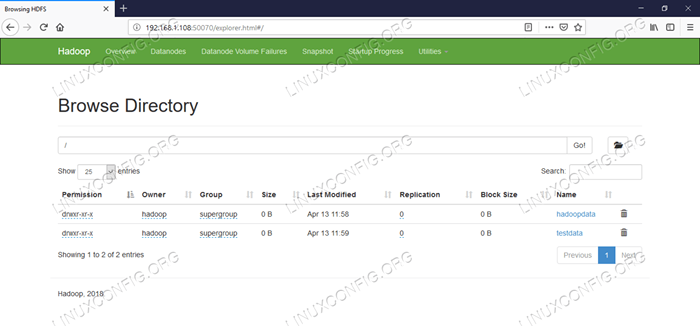 Navegación de directorio HDFS.
Navegación de directorio HDFS. La interfaz web de Yarn Resource Manager (RM) mostrará todos los trabajos en ejecución en el clúster Hadoop actual.
Ui web administrador de recursos - http: //: 8088
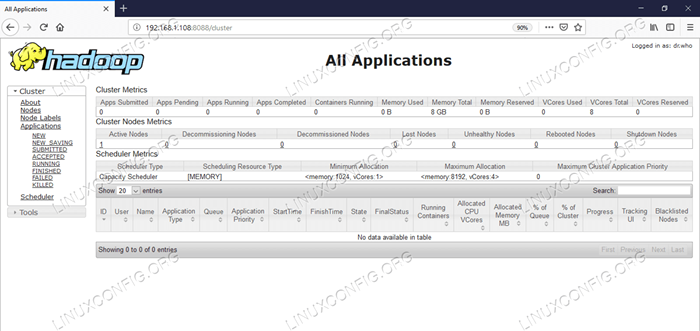 Interfaz de usuario web Administrador de recursos (HILAR).
Interfaz de usuario web Administrador de recursos (HILAR). Conclusión
El mundo está cambiando la forma en que está operando actualmente y los grandes datos están jugando un papel importante en esta fase. Hadoop es un marco que hace que nuestra vida sea fácil mientras trabaja en grandes conjuntos de datos. Hay mejoras en todos los frentes. El futuro es emocionante.
Tutoriales de Linux relacionados:
- Ubuntu 20.04 Hadoop
- Cosas para instalar en Ubuntu 20.04
- Cómo crear un clúster de Kubernetes
- Cómo instalar Kubernetes en Ubuntu 20.04 fossa focal Linux
- Cómo instalar Kubernetes en Ubuntu 22.04 Jellyfish de Jammy ..
- Cosas que hacer después de instalar Ubuntu 20.04 fossa focal Linux
- Cosas para instalar en Ubuntu 22.04
- Cómo trabajar con la API REST de WooCommerce con Python
- Cómo administrar los grupos de Kubernetes con Kubectl
- Una introducción a la automatización, herramientas y técnicas de Linux
- « Cómo instalar WordPress.COM Aplicación de escritorio en Ubuntu 19.04 disco dingo Linux
- Cómo instalar Redmine en Rhel 8 / Centos 8 Linux »