

Cómo instalar clúster de nodo único Hadoop (pseudonode) en Centos 7

- 1034
- 41
- Jaime Delgadillo
Hadoop es un marco de código abierto que se usa ampliamente para tratar Data. La mayoría de BigData/Analytics de datos Se están construyendo proyectos sobre el Ecosistema de Hadoop. Consiste en dos capas, uno es para Almacenamiento de datos Y otro es para Procesando datos.
Almacenamiento será atendido por su propio sistema de archivos llamado HDFS (Sistema de archivos distribuido Hadoop) y Procesando será atendido por HILO (Otro negociador de recursos más). Mapa reducido es el motor de procesamiento predeterminado del Ecosistema de Hadoop.
Este artículo describe el proceso para instalar el Seudonodo Instalación de Hadoop, donde todos los demonios (JVMS) estará ejecutando Nodo único Agrupar Centos 7.
Esto es principalmente para principiantes para aprender Hadoop. En tiempo real, Hadoop se instalará como un clúster multinodo donde los datos se distribuirán entre los servidores como bloques y el trabajo se ejecutará de manera paralela.
Requisitos previos
- Una instalación mínima del servidor CentOS 7.
- Java V1.8 lanzamiento.
- Hadoop 2.X lanzamiento estable.
En esta página
- Cómo instalar Java en Centos 7
- Configurar inicio de sesión sin contraseña en Centos 7
- Cómo instalar el nodo único Hadoop en Centos 7
- Cómo configurar Hadoop en Centos 7
- Formateo del sistema de archivos HDFS a través de NameNode
Instalación de Java en Centos 7
1. Hadoop es un ecosistema que se compone de Java. Nosotros necesitamos Java instalado en nuestro sistema obligatoriamente para instalar Hadoop.
# yum instalar java-1.8.0-Openjdk
2. A continuación, verifique la versión instalada de Java en el sistema.
# java -version
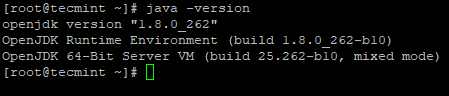 verifica la versión de Java
verifica la versión de Java Configurar inicio de sesión sin contraseña en Centos 7
Necesitamos tener SSH configurado en nuestra máquina, Hadoop administrará nodos con el uso de Ssh. Master Node usa Ssh conexión para conectar sus nodos esclavos y realizar operaciones como Start and Stop.
Necesitamos configurar SSH sin contraseña para que el maestro pueda comunicarse con esclavos usando SSH sin contraseña. De lo contrario, para cada establecimiento de conexión, debe ingresar la contraseña.
En este nodo único, Maestro servicios (Namenode, Namenode secundario Y Administrador de recursos) y Esclavo servicios (Datanode Y Nodo) se ejecutará como separado JVMS. Aunque es el nodo Singe, necesitamos tener una SSH sin contraseña para hacer Maestro comunicar Esclavo sin autenticación.
3. Configure un inicio de sesión SSH sin contraseña utilizando los siguientes comandos en el servidor.
# ssh-keygen # ssh-copy-id -i localhost
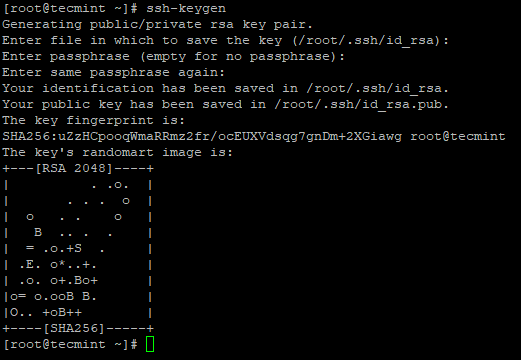 Crear ssh keygen en centos 7
Crear ssh keygen en centos 7 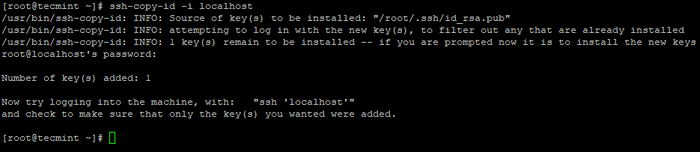 Copiar la tecla SSH a Centos 7
Copiar la tecla SSH a Centos 7 4. Después de configurar el inicio de sesión SSH sin contraseña, intente iniciar sesión nuevamente, estará conectado sin una contraseña.
# ssh localhost
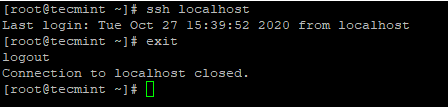 SSH Iniciar sesión sin contraseña en Centos 7
SSH Iniciar sesión sin contraseña en Centos 7 Instalación de Hadoop en Centos 7
5. Vaya al sitio web de Apache Hadoop y descargue la versión estable de Hadoop utilizando el siguiente comando wget.
# wget https: // Archive.apache.org/Dist/Hadoop/Core/Hadoop-2.10.1/Hadoop-2.10.1.alquitrán.gz # tar xvpzf hadoop-2.10.1.alquitrán.GZ
6. A continuación, agregue el Hadoop Variables de entorno en ~/.bashrc archivo como se muestra.
Hadoop_prefix =/root/hadoop-2.10.1 ruta = $ ruta: $ hadoop_prefix/bin exportación ruta java_home hadoop_prefix
7. Después de agregar variables de entorno a ~/.bashrc el archivo, obtener el archivo y verificar el hadoop ejecutando los siguientes comandos.
# fuente ~/.BASHRC # CD $ Hadoop_prefix # bin/hadoop versión
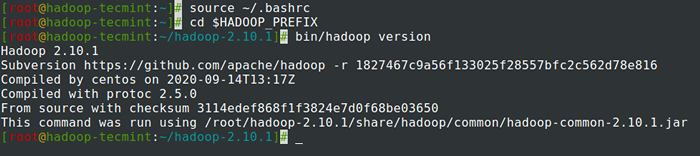 Consulte la versión de Hadoop en Centos 7
Consulte la versión de Hadoop en Centos 7 Configuración de Hadoop en Centos 7
Necesitamos configurar los archivos de configuración de Hadoop para caber en su máquina. En Hadoop, Cada servicio tiene su propio número de puerto y su propio directorio para almacenar los datos.
- Archivos de configuración de Hadoop - Core -Site.XML, HDFS-SITE.XML, Mapred-Site.XML y hilo.xml
8. Primero, necesitamos actualizar Java_home y Hadoop camino en el hadoop-env.mierda archivo como se muestra.
# cd $ hadoop_prefix/etc/hadoop # vi hadoop-env.mierda
Ingrese la siguiente línea al comienzo del archivo.
Exportar java_home =/usr/lib/jvm/java-1.8.0/JRE exporta hadoop_prefix =/root/hadoop-2.10.1
9. A continuación, modifique el sitio de núcleo.xml archivo.
# CD $ Hadoop_prefix/etc/Hadoop # VI Core-Site.xml
Pega después de Etiquetas como se muestra.
FS.defaultfs hdfs: // localhost: 9000
10. Cree los directorios a continuación en tecmenta directorio de inicio de usuario, que se utilizará para Nn y Dn almacenamiento.
# mkdir -p/home/tecmint/hdata/ # mkdir -p/home/tecmint/hdata/data # mkdir -p/home/tecmint/hdata/name
10. A continuación, modifique el sitio HDFS.xml archivo.
# CD $ Hadoop_prefix/etc/Hadoop # VI HDFS-Site.xml
Pega después de Etiquetas como se muestra.
DFS.Replicación 1 DFS.namenode.nombre.dir/home/tecmint/hdata/nombre dfs .datanode.datos.Dir Home/TecMint/HData/Data
11. De nuevo, modifique el sitio de mapred.xml archivo.
# cd $ hadoop_prefix/etc/hadoop # cp mapred-site.xml.plantilla mapred-site.XML # VI Mapred-site.xml
Pega después de Etiquetas como se muestra.
Mapa reducido.estructura.hilo de nombre
12. Por último, modifique el hilo.xml archivo.
# CD $ Hadoop_prefix/etc/Hadoop # VI Hyarn Site.xml
Pega después de Etiquetas como se muestra.
hilo.nodo.Aux-Services MapReduce_Shuffle
Formateo del sistema de archivos HDFS a través de NameNode
13. Antes de comenzar el Grupo, Necesitamos formatear el Hadoop nn en nuestro sistema local donde se ha instalado. Por lo general, se hará en la etapa inicial antes de comenzar el clúster la primera vez.
Formatear el Nn Causará la pérdida de datos en NN Metastore, por lo que tenemos que ser más cautelosos, no debemos formatear Nn mientras el clúster se ejecuta a menos que se requiera intencionalmente.
# cd $ hadoop_prefix # bin/hadoop namenode -format
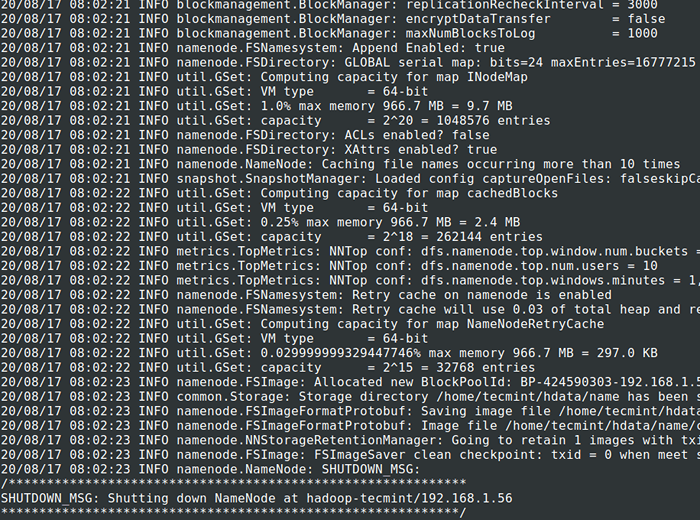 Formato de sistema de archivos HDFS
Formato de sistema de archivos HDFS 14. Comenzar Namenode demonio y Datanode Daemon: (Puerto 50070).
# cd $ hadoop_prefix # sbin/start-dfs.mierda
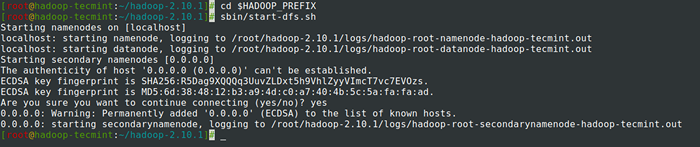 Iniciar NameNode y Datanode Daemon
Iniciar NameNode y Datanode Daemon 15. Comenzar Administrador de recursos demonio y Nodo Daemon: (Puerto 8088).
# sbin/start-yarn.mierda
 Iniciar ResourceManager y Nodemanager Daemon
Iniciar ResourceManager y Nodemanager Daemon dieciséis. Para detener todos los servicios.
# sbin/stop-dfs.sh # sbin/stop-dfs.mierda
Resumen
Resumen
En este artículo, hemos pasado por el proceso paso a paso para configurar Hadoop seudonode (Nodo único) Grupo. Si tiene conocimiento básico de Linux y sigue estos pasos, el clúster estará en 40 minutos.
Esto puede ser muy útil para el principiante para comenzar a aprender y practicar Hadoop o esta versión de vainilla de Hadoop se puede utilizar para fines de desarrollo. Si queremos tener un clúster en tiempo real, necesitamos al menos 3 servidores físicos en la mano o tenemos que aprovisionar la nube para tener múltiples servidores.
- « Configuración de requisitos previos y endurecimiento de seguridad de Hadoop - Parte 2
- ¿Qué es MongoDB?? ¿Cómo funciona MongoDB?? »