

Introducción al raspado web de Python y la hermosa biblioteca de sopa
- 2336
- 598
- Sr. Eduardo Menchaca
Objetivo
Aprender a extraer información de una página HTML usando Python y la hermosa biblioteca de sopa.
Requisitos
- Comprensión de los conceptos básicos de Python y Programación orientada a objetos
Convenciones
- # - requiere que el comando Linux dado se ejecute con privilegios raíz
directamente como usuario raíz o mediante el uso desudodominio - ps - Dado el comando Linux para ser ejecutado como un usuario regular no privilegiado
Introducción
El raspado web es una técnica que consiste en la extracción de datos de un sitio web mediante el uso de software dedicado. En este tutorial veremos cómo realizar un raspado web básico con Python y la hermosa biblioteca de sopa. Usaremos python3 Dirigido a la página de inicio de Rotten Tomatoes, el famoso agregador de reseñas y noticias para películas y programas de televisión, como fuente de información para nuestro ejercicio.
Instalación de la hermosa biblioteca de sopa
Para realizar nuestro raspado, haremos uso de la hermosa biblioteca de sopa Python, por lo tanto, lo primero que debemos hacer es instalarlo. La biblioteca está disponible en los repositorios de todas las principales distribuciones de Gnu \ Linux, por lo tanto, podemos instalarla utilizando nuestro Administrador de paquetes favorito o utilizando pepita, la forma nativa de Python para instalar paquetes.
Si se prefiere el uso del Administrador de paquetes de distribución y estamos utilizando Fedora:
$ sudo dnf install python3-beautifulsoup4
En Debian y sus derivados, el paquete se llama BeautifulSoup4:
$ sudo apt-get install beautifulSoup4
En Archilinux podemos instalarlo a través de Pacman:
$ sudo Pacman -S Python -Beatufilusoup4
Si queremos usar pepita, En cambio, podemos ejecutar:
$ PIP3 Install -User BeautifulSoup4
Ejecutando el comando anterior con el --usuario Flag, instalaremos la última versión de la hermosa biblioteca de sopa solo para nuestro usuario, por lo tanto, no se necesitan permisos raíz. Por supuesto, puede decidir usar PIP para instalar el paquete a nivel mundial, pero personalmente tiendo a preferir las instalaciones por usuario cuando no use el Administrador de paquetes de distribución.
El objeto beautifulsoup
Comencemos: lo primero que queremos hacer es crear un objeto hermoso. El constructor de bellowSoup acepta un cadena o un mango de archivo como su primer argumento. Esto último es lo que nos interesa: tenemos la URL de la página que queremos raspar, por lo tanto, usaremos el urgente método del urllib.pedido biblioteca (instalada por defecto): este método devuelve un objeto similar a un archivo:
de bs4 import beautifulsoup de urllib.Solicite importar Urlopen con Urlopen ('http: // www.tomates podridos.com ') como página de inicio: sopa = beautifulsoup (página de inicio) En este punto, nuestra sopa está lista: el sopa El objeto representa el documento en su totalidad. Podemos comenzar a navegarlo y extraer los datos que queremos utilizando los métodos y propiedades incorporados. Por ejemplo, digamos que queremos extraer todos los enlaces contenidos en la página: sabemos que los enlaces están representados por el a etiqueta en html y el enlace real está contenido en el href atributo de la etiqueta, para que podamos usar el encuentra todos Método del objeto que acabamos de construir para realizar nuestra tarea:
para enlace en sopa.find_all ('a'): print (enlace.Get ('href')) Mediante el uso del encuentra todos método y especificación a Como primer argumento, que es el nombre de la etiqueta, buscamos todos los enlaces en la página. Para cada enlace, recuperamos e imprimimos el valor del href atributo. En Beautifulsoup, los atributos de un elemento se almacenan en un diccionario, por lo tanto, recuperarlos es muy fácil. En este caso usamos el conseguir Método, pero podríamos haber accedido al valor del atributo HREF incluso con la siguiente sintaxis: enlace ['href']. El diccionario de atributos completos en sí está contenido en el atacantes Propiedad del elemento. El código anterior producirá el siguiente resultado:
[…] Https: // editorial.tomates podridos.com/https: // editorial.tomates podridos.com/24 frames/https: // editorial.tomates podridos.com/binge-guide/https: // editorial.tomates podridos.com/box-office-guru/https: // editorial.tomates podridos.com/crítico-consensus/https: // editorial.tomates podridos.com/cinco-films/https: // editorial.tomates podridos.com/ahora-streaming/https: // editorial.tomates podridos.com/parental-guía/https: // editorial.tomates podridos.com/rojo-carpet-roundup/https: // editorial.tomates podridos.com/rt-on-dvd/https: // editorial.tomates podridos.com/the-Simpsons-decade/https: // editorial.tomates podridos.com/subcult/https: // editorial.tomates podridos.com/tech-talk/https: // editorial.tomates podridos.com/ Total-Recall/ […]
La lista es mucho más larga: lo anterior es solo un extracto de la salida, pero le da una idea. El encuentra todos El método devuelve todo Etiqueta objetos que coinciden con el filtro especificado. En nuestro caso, acabamos de especificar el nombre de la etiqueta que debe coincidir, y no hay otros criterios, por lo que se devuelven todos los enlaces: veremos en un momento cómo restringir aún más nuestra búsqueda.
Un caso de prueba: recuperar todos los títulos de "taquilla superior"
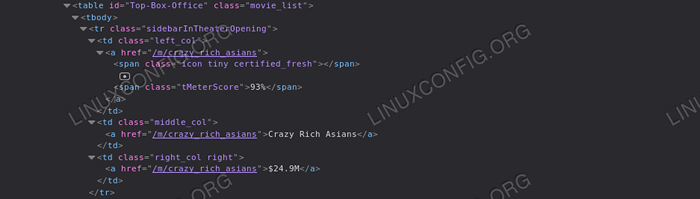
Realicemos un raspado más restringido. Digamos que queremos recuperar todos los títulos de las películas que aparecen en la sección de "taquilla superior" de la página de inicio de Rotten Tomatoes. Lo primero que queremos hacer es analizar la página HTML para esa sección: al hacerlo, podemos observar que el elemento que necesitamos está contenido dentro de un mesa elemento con la "oficina superior" identificación:
Taquilla superior También podemos observar que cada fila de la tabla contiene información sobre una película: los puntajes del título están contenidos como texto dentro de un durar Elemento con clase "TMeterscore" dentro de la primera celda de la fila, mientras que la cadena que representa el título de la película está contenida en la segunda celda, como el texto del a etiqueta. Finalmente, la última celda contiene un enlace con el texto que representa los resultados de la taquilla de la película. Con esas referencias, podemos recuperar fácilmente todos los datos que queremos:
de bs4 import beautifulsoup de urllib.Solicitar la importación de Urlopen con Urlopen ('https: // www.tomates podridos.com ') como página de inicio: sopa = beautifulsoup (página de inicio.leer (), 'html.parser ') # Primero usamos el método Buscar para recuperar la tabla con la id' top-box-ofice 'top_box_office_table = sopa.find ('table', 'id': 'top-box-ofice') # de lo que iteramos sobre cada fila y extrae información de películas para fila en top_box_office_table.find_all ('tr'): celdas = fila.find_all ('td') title = celdas [1].encontrar un').get_text () dinero = celdas [2].encontrar un').get_text () stork = fila.find ('span', 'class': 'tmeterscore').get_text () print ('0 - 1 (tomatómetro: 2)'.formato (título, dinero, puntaje)) El código anterior producirá el siguiente resultado:
Asiáticos ricos locos - $ 24.9m (tomatómetro: 93%) el Meg - $ 12.9m (tomatómetro: 46%) Los asesinatos de tiempo feliz - \ $ 9.6m (tomatómetro: 22%) Misión: Imposible - Fallout - $ 8.2m (tomatómetro: 97%) milla 22 - $ 6.5m (tomatómetro: 20%) Christopher Robin - $ 6.4m (tomatómetro: 70%) alfa - $ 6.1M (Tomatómetro: 83%) Blackkklansman - $ 5.2m (tomatómetro: 95%) Slender Man - $ 2.9m (tomatómetro: 7%) A.X.L. -- $ 2.8m (tomatómetro: 29%)
Presentamos algunos elementos nuevos, veamos. Lo primero que hemos hecho es recuperar el mesa con 'top-box-office' ID, usando el encontrar método. Este método funciona de manera similar a encuentra todos, Pero si bien este último devuelve una lista que contiene las coincidencias encontradas, o está vacía si no hay correspondencia, el primero devuelve siempre el primer resultado o Ninguno Si no se encuentra un elemento con los criterios especificados.
El primer elemento proporcionado al encontrar El método es el nombre de la etiqueta a considerar en la búsqueda, en este caso mesa. Como segundo argumento, aprobamos un diccionario en el que cada clave representa un atributo de la etiqueta con su valor correspondiente. Los pares de valor clave proporcionados en el diccionario representan los criterios que deben satisfacerse para que nuestra búsqueda produzca una coincidencia. En este caso buscamos el identificación Atributo con el valor "Top-Box-Office". Observe que desde cada uno identificación Debemos ser únicos en una página HTML, podríamos haber omitido el nombre de la etiqueta y usar esta sintaxis alternativa:
top_box_office_table = sopa.find (id = 'top-box-office') Una vez que recuperamos nuestra mesa Etiqueta objeto, usamos el encuentra todos método para encontrar todas las filas e iterar sobre ellas. Para recuperar los otros elementos, utilizamos los mismos principios. También utilizamos un nuevo método, get_text: Devuelve solo la parte de texto contenida en una etiqueta, o si no se especifica ninguna, en toda la página. Por ejemplo, saber que el porcentaje de puntuación de la película está representado por el texto contenido en el durar elemento con el tmeterscore clase, usamos el get_text método en el elemento para recuperarlo.
En este ejemplo, acabamos de mostrar los datos recuperados con un formato muy simple, pero en un escenario del mundo real, podríamos haber querido realizar más manipulaciones o almacenarlos en una base de datos.
Conclusiones
En este tutorial, acabamos de rascar la superficie de lo que podemos hacer con Python y una hermosa biblioteca de sopa para realizar el raspado web. La biblioteca contiene muchos métodos que puede usar para una búsqueda más refinada o para navegar mejor la página: para esto recomiendo consultar los documentos oficiales muy bien escritos.
Tutoriales de Linux relacionados:
- Cosas para instalar en Ubuntu 20.04
- Una introducción a la automatización, herramientas y técnicas de Linux
- Cosas que hacer después de instalar Ubuntu 20.04 fossa focal Linux
- Mastering Bash Script Loops
- Mint 20: Mejor que Ubuntu y Microsoft Windows?
- Comandos de Linux: los 20 comandos más importantes que necesitas ..
- Comandos básicos de Linux
- Cómo construir una aplicación Tkinter utilizando un objeto orientado ..
- Ubuntu 20.04 WordPress con instalación de Apache
- Cómo montar la imagen ISO en Linux