

Eliminar líneas duplicadas de un archivo de texto utilizando la línea de comandos de Linux
- 2400
- 653
- Sr. Eduardo Menchaca
Eliminar líneas duplicadas de un archivo de texto se puede hacer desde la línea de comandos de Linux. Tal tarea puede ser más común y necesaria de lo que piensas. El escenario más común donde esto puede ser útil es con los archivos de registro. A menudo los archivos de registro repetirán la misma información una y otra vez, lo que hace que el archivo sea casi imposible de examinar, a veces lo que hace que los registros inútiles.
En esta guía, mostraremos varios ejemplos de línea de comandos que puede usar para eliminar líneas duplicadas de un archivo de texto. Pruebe algunos de los comandos en su propio sistema y use el que sea más conveniente para su escenario.
En este tutorial aprenderás:
- Cómo eliminar las líneas duplicadas del archivo al clasificar
- Cómo contar el número de líneas duplicadas en un archivo
- Cómo eliminar las líneas duplicadas sin ordenar el archivo
Varios ejemplos para eliminar líneas duplicadas de un archivo de texto en Linux | Categoría | Requisitos, convenciones o versión de software utilizada |
|---|---|
| Sistema | Cualquier distribución de Linux |
| Software | Cáscara |
| Otro | Acceso privilegiado a su sistema Linux como root o a través del sudo dominio. |
| Convenciones | # - requiere que los comandos de Linux dados se ejecuten con privilegios raíz directamente como un usuario raíz o mediante el uso de sudo dominiops - Requiere que los comandos de Linux dados se ejecuten como un usuario regular no privilegiado |
Eliminar líneas duplicadas del archivo de texto
Estos ejemplos funcionarán en cualquier distribución de Linux, siempre que esté utilizando el shell bash.
Para nuestro escenario de ejemplo, trabajaremos con el siguiente archivo, que solo contiene los nombres de varias distribuciones de Linux. Este es un archivo de texto muy simple en aras del ejemplo, pero en realidad podría usar estos métodos en documentos que contienen incluso miles de líneas de repetición. Veremos cómo eliminar todos los duplicados de este archivo utilizando los ejemplos a continuación.
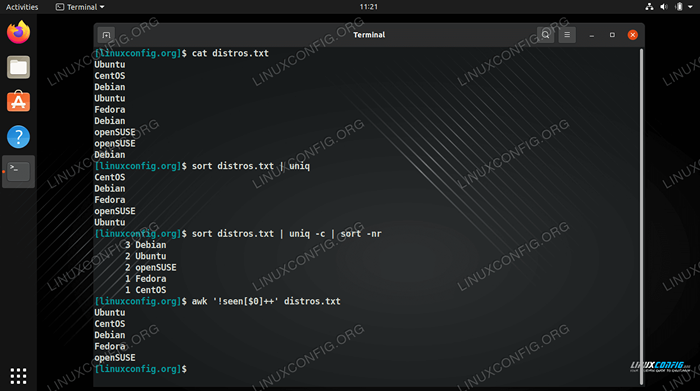
$ Cat Distross.txt ubuntu centos Debian Ubuntu Fedora Debian OpenSuse OpenSuse Debian
- El
uniqEl comando puede aislar todas las líneas únicas de nuestro archivo, pero esto solo funciona si las líneas duplicadas son adyacentes entre sí. Para que las líneas sean adyacentes, primero tendrían que clasificarse en orden alfabético. El siguiente comando funcionaría usandoclasificaryuniq.$ sort Distros.txt | Uniq Centos Debian Fedora OpenSuse Ubuntu
Para facilitar las cosas, podemos usar el
-ucon clases para obtener el mismo resultado exacto, en lugar de tuvo a UNIQ.
$ sort -u distribuys.Txt Centos Debian Fedora OpenSuse Ubuntu
- Para ver cuántas ocurrencias de cada línea hay en el archivo, podemos usar el
-C(contar) opción con uniq.$ sort Distros.txt | Uniq -C 1 Centos 3 Debian 1 Fedora 2 OpenSuse 2 Ubuntu
- Para ver las líneas que se repiten con mayor frecuencia, podemos llevar a otro comando de clasificación con el
-norte(clasificación numérica) y-riñonalOpciones de reversa. Esto nos permite ver rápidamente qué líneas están más duplicadas en el archivo: otra opción útil para examinar los registros.$ sort Distros.txt | uniq -c | Sort -nr 3 Debian 2 Ubuntu 2 OpenSuse 1 Fedora 1 Centos
- Un problema con el uso de los comandos anteriores es que confiamos en
clasificar. Esto significa que nuestra salida final está ordenada alfabéticamente o se clasifica por la cantidad de repeticiones como en el ejemplo anterior. Esto puede ser algo bueno a veces, pero ¿qué pasa si necesitamos el archivo de texto para conservar su pedido anterior?? Podemos eliminar líneas duplicadas sin ordenar el archivo utilizando elasombrarComando en la siguiente sintaxis.$ awk '!Visto [$ 0] ++ 'Distross.Txt Ubuntu Centos Debian Fedora OpenSuse
Con este comando, se mantiene la primera aparición de una línea y las líneas duplicadas futuras se desechan de la salida.
- Los ejemplos anteriores enviarán salida directamente a su terminal. Si desea un nuevo archivo de texto con sus líneas duplicadas filtradas, puede adaptar cualquiera de estos ejemplos simplemente usando el
>Operador de bash como en el siguiente comando.$ awk '!Visto [$ 0] ++ 'Distross.txt> Distros-Nuevo.TXT
Estos deben ser todos los comandos que necesita para soltar líneas duplicadas desde un archivo, mientras opcionalmente clasifica o contaba las líneas. Existen más métodos, pero estos son los más fáciles de usar y recordar.
Pensamientos de cierre
En esta guía, vimos varios ejemplo de comando para eliminar las líneas duplicadas de un archivo de texto en Linux. Puede aplicar estos comandos a los archivos de registro o cualquier otro tipo de archivo de texto sin formato que tenga líneas duplicadas. También aprendimos cómo ordenar las líneas de un archivo de texto o contar el número de duplicados, ya que eso a veces puede acelerar aislar la información que necesitamos de un documento.
Tutoriales de Linux relacionados:
- Cosas para instalar en Ubuntu 20.04
- Cómo mejorar la representación de fuentes de Firefox en Linux
- Una introducción a la automatización, herramientas y técnicas de Linux
- Mastering Bash Script Loops
- Cosas que hacer después de instalar Ubuntu 20.04 fossa focal Linux
- Comandos de Linux: los 20 comandos más importantes que necesitas ..
- Comandos básicos de Linux
- Cómo montar la imagen ISO en Linux
- Archivos de configuración de Linux: los 30 principales más importantes
- Ejemplos de RSYNC en Linux