

Hadoop - Ejemplo de MapReduce de la cuenta de Word
- 4055
- 603
- Hugo Vera
Este tutorial lo ayudará a ejecutar un ejemplo de MapReduce de WordCount en Hadoop usando la línea de comandos. Esta puede ser también una prueba inicial para su prueba de configuración de Hadoop.
1. Requisitos previos
Debe haber ejecutado la configuración de Hadoop en su sistema. Si no tiene instalado Hadoop, visite la instalación de Hadoop en el tutorial de Linux.
2. Copiar archivos a NameNode FileSystem
Después de formatear con éxito Namenode, debe haber iniciado todos los servicios de Hadoop correctamente. Ahora cree un directorio en el sistema de archivos de Hadoop.
$ hdfs dfs -mkdir -p/user/hadoop/input
Copiar copiar algún archivo de texto al sistema de archivos Hadoop dentro del directorio de entrada. Aquí estoy copiando licencia.txt a él. Puede copiar más que uno de los archivos.
$ hdfs dfs -put licencia.txt/user/hadoop/input/
3. Ejecutando el comando WordCount
Ahora ejecute el ejemplo de WordCount MapReduce usando el siguiente comando. El siguiente comando leerá todos los archivos de la carpeta de entrada y procesará con el archivo MapReduce JAR. Después de la finalización exitosa de los resultados de la tarea, se colocarán en el directorio de salida.
$ cd $ hadoop_home $ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-pruebas-2.6.0.Salida de entrada Jar WordCount
4. Mostrar resultados
Primero verifique los nombres del archivo de resultados creado en [Correo electrónico protegido]/user/hadoop/output FileSystem utilizando el siguiente comando.
$ HDFS DFS -LS/User/Hadoop/Output
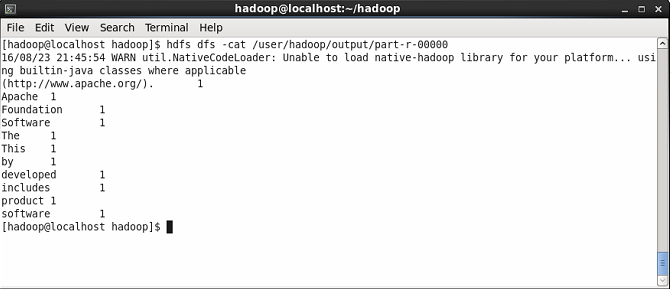
Ahora muestre el contenido del archivo de resultados donde verá el resultado de WordCount. Verás el recuento de cada palabra.
$ HDFS DFS -CAT/USER/HADOOP/Output/Part-R-00000
- « Cómo instalar Go 1.19 en Fedora 36/35 & Centos/Rhel 8/7
- Cómo instalar Apache Maven en CentOS/RHEL 8/7 »