

Cómo configurar y mantener una alta disponibilidad/agrupación en Linux
- 2340
- 579
- Claudia Baca
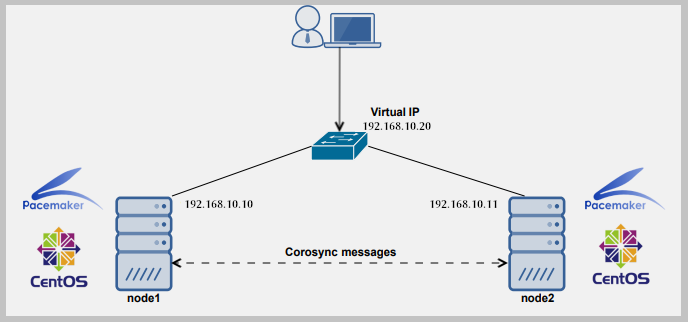
Alta disponibilidad (JA) simplemente se refiere a la calidad de un sistema para operar continuamente sin falla durante un largo período de tiempo. Las soluciones de HA se pueden implementar utilizando hardware y/o software, y una de las soluciones comunes para la implementación de HA se agrupa.
En la computación, un clúster está compuesto por dos o más computadoras (comúnmente conocidas como nodos o miembros) que trabajan juntos para realizar una tarea. En dicha configuración, solo un nodo proporciona al servicio los nodos secundarios que se apoderan de si falla.
Los grupos caen en cuatro tipos principales:
- Almacenamiento: Proporcione una imagen de sistema de archivos consistente en los servidores en un clúster, lo que permite que los servidores lean y escriban simultáneamente a un solo sistema de archivos compartidos.
- Alta disponibilidad: Elimine los puntos de falla individuales y al fallar sobre los servicios de un nodo de clúster a otro en caso de que salga un nodo no sea operativo.
- Balanceo de carga: Enviar solicitudes de servicio de red a múltiples nodos de clúster para equilibrar la carga de solicitud entre los nodos de clúster.
- Alto rendimiento: llevar a cabo un procesamiento paralelo o concurrente, lo que ayuda a mejorar el rendimiento de las aplicaciones.
Otra solución ampliamente utilizada para proporcionar JA es replicación (específicamente replicaciones de datos). La replicación es el proceso por el cual una o más bases de datos (secundarias) se pueden mantener sincronizadas con una sola base de datos primaria (o maestra).
Para configurar un clúster, necesitamos al menos dos servidores. Para el propósito de esta guía, usaremos dos servidores Linux:
- Nodo1: 192.168.10.10
- Nodo 2: 192.168.10.11
En este artículo, demostraremos los conceptos básicos de cómo implementar, configurar y mantener una alta disponibilidad/agrupación en Ubuntu 16.18/04.04 y Centos 7. Demostraremos cómo agregar el servicio Nginx HTTP al clúster.
Configuración de configuraciones de DNS locales en cada servidor
Para que los dos servidores se comuniquen entre sí, necesitamos configurar la configuración DNS local apropiada en el /etc/huéspedes Archivo en ambos servidores.
Abra y edite el archivo usando su editor de línea de comandos favorito.
$ sudo vim /etc /hosts
Agregue las siguientes entradas con direcciones IP reales de sus servidores.
192.168.10.10 nodo1.ejemplo.com 192.168.10.11 nodo2.ejemplo.comunicarse
Guarde los cambios y cierre el archivo.
Instalación del servidor web Nginx
Ahora instale el servidor web Nginx utilizando los siguientes comandos.
$ sudo apt install nginx [en ubuntu] $ sudo yum instalación epel-release && sudo yum install nginx [en Centos 7]
Una vez que se complete la instalación, inicie el servicio NGINX por ahora y habilite que inicie automáticamente en el momento del arranque, luego verifique si está en funcionamiento usando el comando SystemCTL.
En Ubuntu, el servicio debe iniciarse automáticamente inmediatamente después de que se complete la preconfiguración del paquete, simplemente puede habilitarlo.
$ sudo SystemCtl Enable Nginx $ sudo SystemCtl Inicio Nginx $ sudo SystemCtl Status Nginx
Después de comenzar el servicio NGINX, necesitamos crear páginas web personalizadas para identificar y probar operaciones en ambos servidores. Modificaremos el contenido de la página de índice NGINX predeterminada como se muestra.
$ echo "Esta es la página predeterminada para Node1.ejemplo.com "| sudo tee/usr/share/nginx/html/index.html #vps1 $ echo "Esta es la página predeterminada para node2.ejemplo.com "| sudo tee/usr/share/nginx/html/index.html #vps2
Instalación y configuración de Corosync y Pacemaker
A continuación, tenemos que instalar Marcapasos, Corosync, y Pcs en cada nodo de la siguiente manera.
$ sudo apt install Corosync Pacemaker PCS #ubuntu $ sudo yum instalación Corosync Pacemaker PCS #centos
Una vez que se complete la instalación, asegúrese de que pcs Daemon se está ejecutando en ambos servidores.
$ sudo SystemCTL Habilitar PCSD $ sudo SystemCTL Start PCSD $ SUDO SystemCTL State PCSD
Creando el clúster
Durante la instalación, un usuario del sistema llamó "Hacluster" es creado. Por lo tanto, necesitamos configurar la autenticación necesaria para pcs. Comencemos creando una nueva contraseña para el "Hacluster" Usuario, necesitamos usar la misma contraseña en todos los servidores:
$ sudo passwd hacluster
 Crear contraseña de usuario de clúster
Crear contraseña de usuario de clúster A continuación, en uno de los servidores (nodo1), ejecute el siguiente comando para configurar la autenticación necesaria para pcs.
$ sudo PCS Cluster Auth Node1.ejemplo.com nodo2.ejemplo.com -u hacluster -p contraseña_here --force
 Configuración de autenticación para PCS
Configuración de autenticación para PCS Ahora cree un clúster y llénelo con algunos nodos (el nombre del clúster no puede exceder los 15 caracteres, en este ejemplo, hemos usado exámenes exámenes) en el servidor Node1.
Configuración de clúster de PCS $ sudo -Node de nombre de nombre.ejemplo.com nodo2.ejemplo.comunicarse
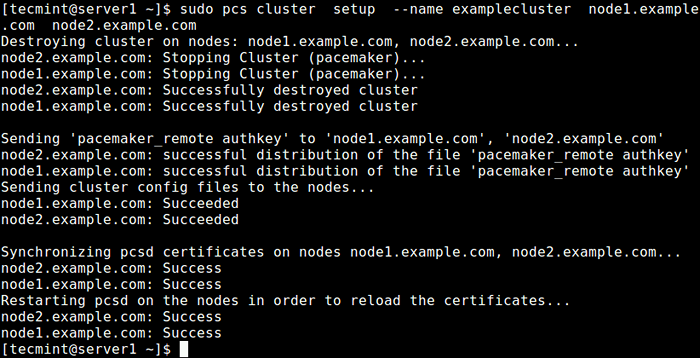 Crear clúster en el nodo1
Crear clúster en el nodo1 Ahora habilite el clúster en el arranque e inicie el servicio.
$ sudo PCS Cluster Enable -All $ sudo PCS Cluster Start -todo
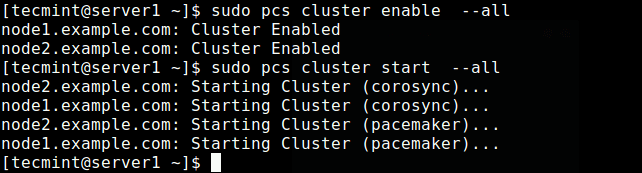 Habilitar y comenzar el clúster
Habilitar y comenzar el clúster Ahora verifique si el servicio de clúster está en funcionamiento usando el siguiente comando.
$ sudo PCS Status o $ sudo CRM_MON -1
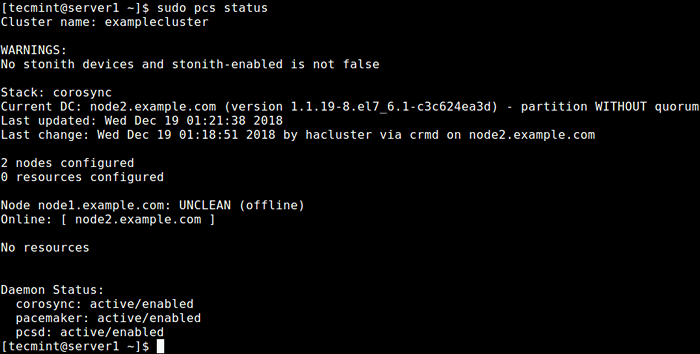 Verifique el estado del clúster
Verifique el estado del clúster De la salida del comando anterior, puede ver que hay una advertencia sobre no Ronca dispositivos pero el Ronca todavía está habilitado en el clúster. Además, no se han configurado recursos/servicios de clúster.
Configuración de opciones de clúster
La primera opción es deshabilitar Ronca (o Dispara al otro nodo en la cabeza), la implementación de esgrima en Marcapasos.
Este componente ayuda a proteger sus datos de ser corrompidos por el acceso concurrente. Para el propósito de esta guía, lo deshabilitaremos ya que no hemos configurado ningún dispositivo.
Apagar Ronca, Ejecute el siguiente comando:
$ sudo PCS PROPIEDAD SET Stonith-habilitado = FALSO
A continuación, también ignore el Quórum Política ejecutando el siguiente comando:
$ sudo PCS PROPIEDAD SET NO-QUORUM-POLICY = IGNORE
Después de configurar las opciones anteriores, ejecute el siguiente comando para ver la lista de propiedades y asegúrese de que las opciones anteriores, ronca y el política de quórum se desactivan.
Lista de propiedades de $ sudo PCS
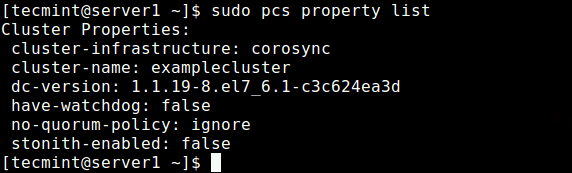 Ver propiedades del clúster
Ver propiedades del clúster Agregar un servicio de recursos/clúster
En esta sección, veremos cómo agregar un recurso de clúster. Configuraremos una IP flotante que es la dirección IP que se puede mover instantáneamente de un servidor a otro dentro de la misma red o centro de datos. En resumen, una IP flotante es un término común técnico, utilizado para IP que no están vinculados estrictamente a una sola interfaz.
En este caso, se utilizará para apoyar la conmutación por error en un grupo de alta disponibilidad. Tenga en cuenta que las IP flotantes no son solo para situaciones de conmutación por error, tienen algunos otros casos de uso. Necesitamos configurar el clúster de tal manera que solo el miembro activo del clúster "posee" o responde a la IP flotante en cualquier momento dado.
Agregaremos dos recursos de clúster: el recurso de dirección IP flotante llamado "flotante_ip"Y un recurso para el servidor web NGINX llamado"http_server".
Primero comience agregando el Floating_IP de la siguiente manera. En este ejemplo, nuestra dirección IP flotante es 192.168.10.20.
$ sudo PCS Resource Cree Floating_IP OCF: Heartbeat: iPaddr2 IP = 192.168.10.20 CIDR_NETMASK = 24 OP Monitor Interval = 60s
dónde:
- flotante_ip: es el nombre del servicio.
- "OCF: Heartbeat: iPaddr2": le dice a Pacemaker qué script usar, ipaddr2 en este caso, en qué espacio de nombres se encuentra (marcapasos) y qué estándar conforma a OCF.
- "Intervalo de monitor OP = 60S": Indica al marcapasos que verifique la salud de este servicio cada uno de los minutos llamando a la acción del monitor del agente.
Luego agregue el segundo recurso, nombrado http_server. Aquí, el agente de recursos del servicio es OCF: Heartbeat: Nginx.
$ sudo PCS Resource Crear http_server OCF: Heartbeat: Nginx confile = "/etc/nginx/nginx.conf "OP Monitor TimeOut =" 20s "interval =" 60s "
Una vez que haya agregado los servicios de clúster, emita el siguiente comando para verificar el estado de los recursos.
$ sudo recursos de estado de PCS
 Verifique los recursos del clúster
Verifique los recursos del clúster Mirando la salida del comando, los dos recursos agregados: "Floating_ip" y "Http_server" han sido enumerados. El servicio flotante_ip está apagado porque el nodo principal está en funcionamiento.
Si tiene habilitado el firewall en su sistema, debe permitir que todo el tráfico Nginx y todos los servicios de alta disponibilidad a través del firewall para una comunicación adecuada entre nodos:
-------------- CENTOS 7 -------------- $ sudo Firewall-CMD --Permanent --Add-Service = http $ sudo firewall-cmd --Permanent --add-service = alta disponibilidad $ sudo firewall-cmd--Reload -------------- Ubuntu -------------- $ sudo Ufw Permitir http $ sudo Ufw Permitir una alta disponibilidad $ sudo UFW recargar
Prueba de alta disponibilidad/agrupación
El paso final e importante es probar que nuestra configuración de alta disponibilidad funciona. Abra un navegador web y navegue a la dirección 192.168.10.20 Debería ver la página NGINX predeterminada desde el nodo2.ejemplo.comunicarse Como se muestra en la captura de pantalla.
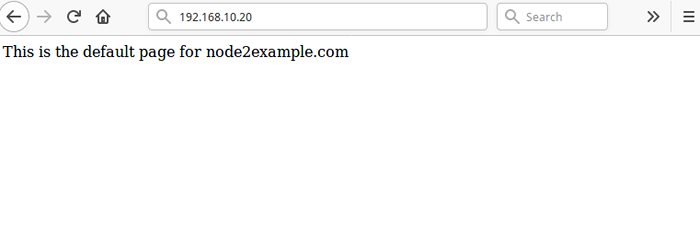 Cluster de prueba antes de la falla
Cluster de prueba antes de la falla Para simular una falla, ejecute el siguiente comando para detener el clúster en el nodo2.ejemplo.comunicarse.
$ sudo PCS Cluster Stop http_server
Luego recargar la página en 192.168.10.20, Ahora debe acceder a la página web NGINX predeterminada desde el nodo1.ejemplo.comunicarse.
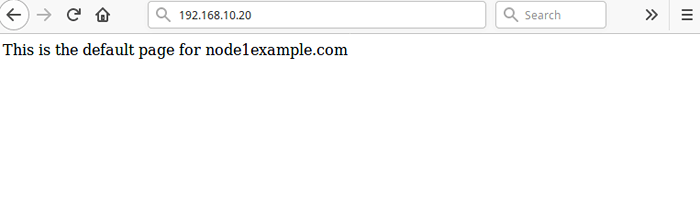 GRUPO DE PRUEBA DESPUÉS DEL FALLA
GRUPO DE PRUEBA DESPUÉS DEL FALLA Alternativamente, puede simular un error diciéndole al servicio que se detenga directamente, sin detener el clúster en cualquier nodo, utilizando el siguiente comando en uno de los nodos:
$ sudo CRM_RESOURCE-Resource http_server --force-stop
Entonces necesitas correr CRM_MON en modo interactivo (el valor predeterminado), dentro del intervalo de monitor de 2 minutos, debe poder ver el clúster notar que http_server falló y muévalo a otro nodo.
Para que sus servicios de clúster se ejecuten de manera eficiente, es posible que deba establecer algunas limitaciones. Puedes ver el pcs Página manual (PCS Man) para una lista de todos los comandos de uso.
Para obtener más información sobre Corosync y Pacemaker, consulte: https: // clusterlabs.org/
Resumen
En esta guía, hemos mostrado los conceptos básicos de cómo implementar, configurar y mantener una alta disponibilidad/agrupación/replicación en Ubuntu 16.18/04.04 y Centos 7. Demostramos cómo agregar el servicio nginx http a un clúster. Si tiene alguna idea para compartir o preguntas, use el formulario de comentarios a continuación.
- « Cómo clonar una partición o disco duro en Linux
- Cómo configurar el cliente LDAP para conectar la autenticación externa »