

Cómo instalar y configurar Hive con alta disponibilidad - Parte 7

- 2436
- 410
- Sta. Enrique Santiago
Colmena es un Almacén de datos modelar Hadoop Ecosistema. Puede funcionar como una herramienta ETL además de Hadoop. Habilitar la alta disponibilidad (HA) en Hive no es similar como lo hacemos en servicios maestros como Namenode y Resource Manager.
La conmutación por error automática no sucederá en Colmena (Hiveserver2). Si alguna Hiveserver2 (HS2) falla, ejecutar trabajos en ese fallado HS2 Obtendrá fallas. Necesitamos volver a enviar el trabajo para que el trabajo pueda ejecutarse en otros Hiveserver2. Entonces, habilitando JA en HS2 no es más que aumentar el número de HS2 componentes en Grupo.
En este artículo, veremos los pasos para instalar y habilitar el Alta disponibilidad de Colmena.
Requisitos
- Las mejores prácticas para implementar el servidor Hadoop en CentOS/RHEL 7 - Parte 1
- Configuración de requisitos previos y endurecimiento de seguridad de Hadoop - Parte 2
- Cómo instalar y configurar el administrador de Cloudera en CentOS/RHEL 7 - Parte 3
- Cómo instalar CDH y configurar las ubicaciones de servicio en CentOS/RHEL 7 - Parte 4
- Cómo configurar una alta disponibilidad para Namenode - Parte 5
- Cómo configurar una alta disponibilidad para el administrador de recursos - Parte 6
Empecemos…
Instalación y configuración de colmena
1. Iniciar sesión en Gerente de Cloudera a la siguiente URL y navegar a Gerente de Cloudera -> Agregar servicio.
http: // 13.233.129.39: 7180/cmf/hogar
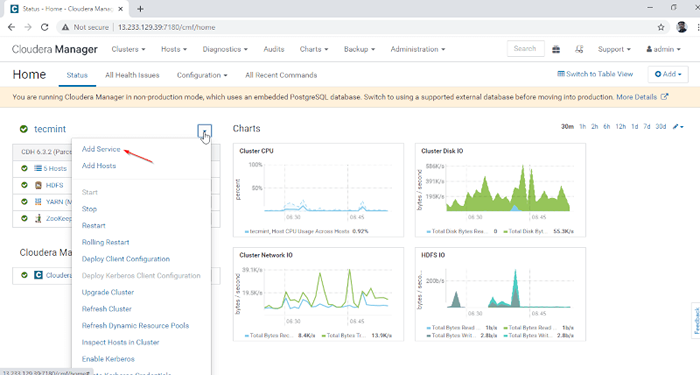 Agregar servicio en Cloudera Manager
Agregar servicio en Cloudera Manager 2. Seleccione el servicio 'Colmena'.
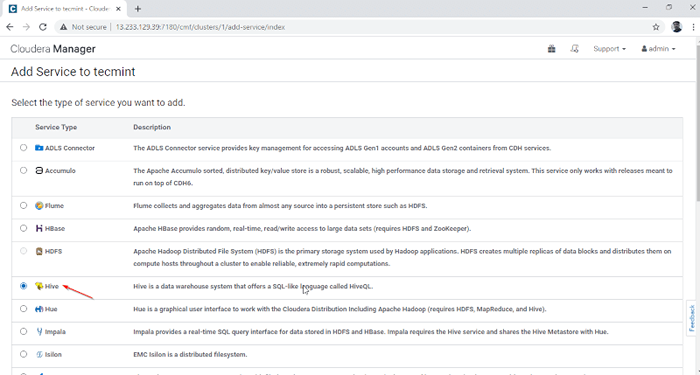 Elija el servicio de colmena
Elija el servicio de colmena 3. Asignar los servicios en los nodos.
- Puerta - Es el servicio al cliente donde el usuario puede acceder a la colmena. Por lo general, este servicio se colocará en Borde nodos dedicados a los usuarios.
- Metastora de colmena - Es un repositorio central para almacenar metadatos de colmena.
- Servidor webhcat - Es una API web para HCatalog y otros servicios de Hadoop.
- Hiveserver2 - Es una interfaz de clientes para la ejecución de consultas en Hive.
Una vez seleccionado los servidores, haga clic ''Continuar' para proceder.
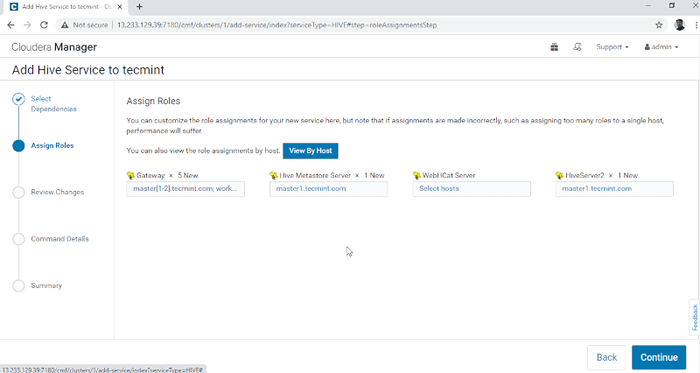 Asignar servicio como nodos
Asignar servicio como nodos 4. Hive Metastore necesita una base de datos subyacente para almacenar metadatos. Aquí estamos usando el valor predeterminado Postgresql base de datos que está incorporada con CDH.
Los detalles de la base de datos mencionados a continuación se ingresarán automáticamente ','Conexión de prueba'se omitirá ya que la base de datos mencionada se creará en la mosca. En tiempo real, necesitamos crear la base de datos en la base de datos externa y probar la conexión para proceder más. Una vez hecho, por favor haga clic en el 'Continuar'.
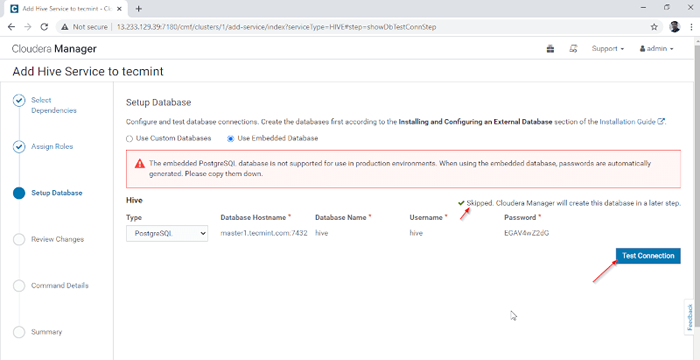 Base de datos de configuración
Base de datos de configuración 5. Configurar el Almacén de colmena directorio, /usuario/colmena/almacén es la ruta de directorio predeterminada para almacenar tablas de colmena. Haga clic en el 'Continuar'.
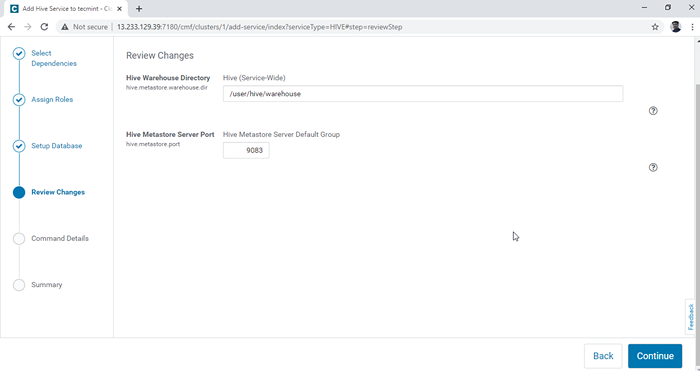 Elija el directorio de almacén de colmena
Elija el directorio de almacén de colmena 6. Se inicia la instalación de colmena.
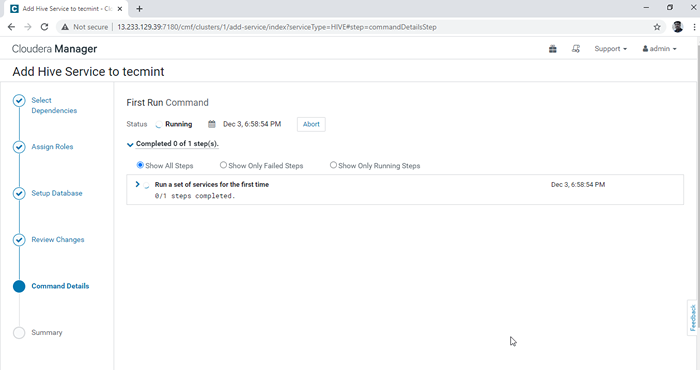 Progreso de instalación de colmena
Progreso de instalación de colmena 7. Una vez completada la instalación, puede obtener el 'Finalizado' estado. Haga clic 'Continuar'Para continuar.
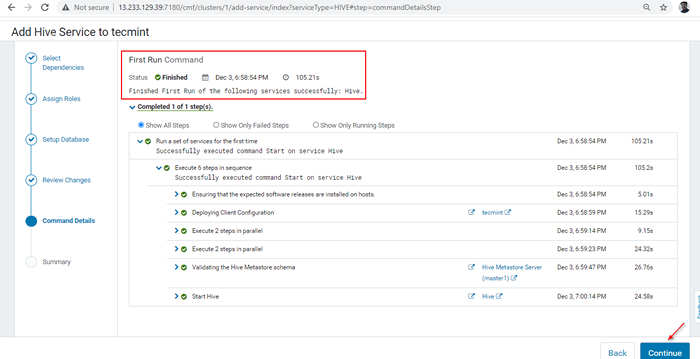 Instalación de colmena terminada
Instalación de colmena terminada 8. Instalación y configuración de colmena completada correctamente. Haga clic 'Finalizar'Para completar el procedimiento de instalación.
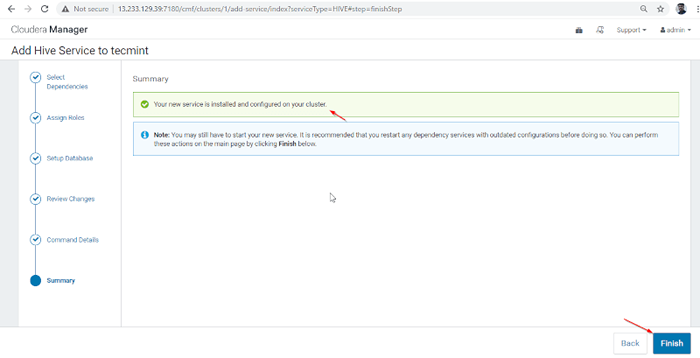 Instalación de Hive Finish
Instalación de Hive Finish 9. Puedes ver el Colmena Servicio agregado en Grupo a través de Panel de control del gerente de Cloudera.
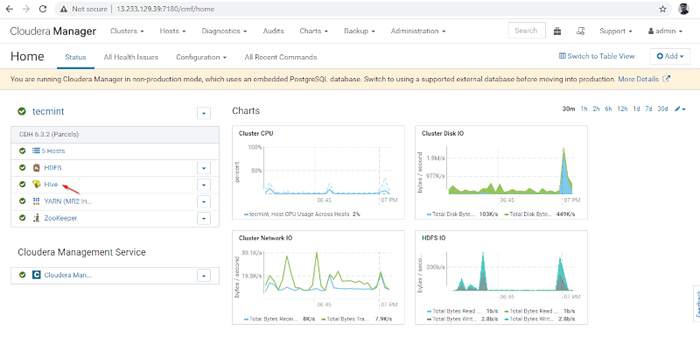 Servicio de colmena agregado
Servicio de colmena agregado 10. Puedes ver el Hiveserver2 en Instancias de Colmena. Hemos agregado Hiveserver2 en maestro1.
Gerente de Cloudera -> Colmena -> Instancias -> Hiveserver2.
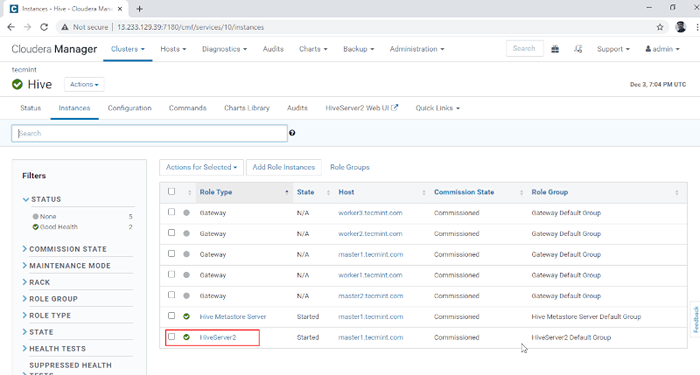 Ver instancias de Hiveserver2
Ver instancias de Hiveserver2 Habilitar una alta disponibilidad en Hive
11. A continuación, agregue el papel de la colmena yendo a Gerente de Cloudera -> Colmena -> Comportamiento -> Agregar rol Instancias.
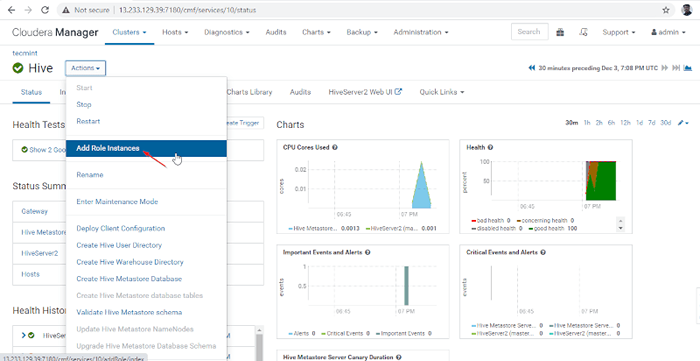 Agregar instancia de rol de colmena
Agregar instancia de rol de colmena 12. Seleccione los servidores donde desea colocar más Hiveserver2. Puedes agregar más de dos, no hay límite. Aquí estamos agregando uno extra Hiveserver2 en maestro2.
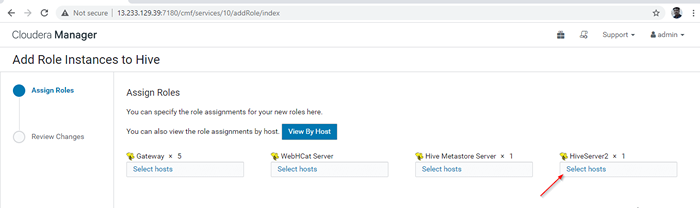 Elija servidor para colmena
Elija servidor para colmena 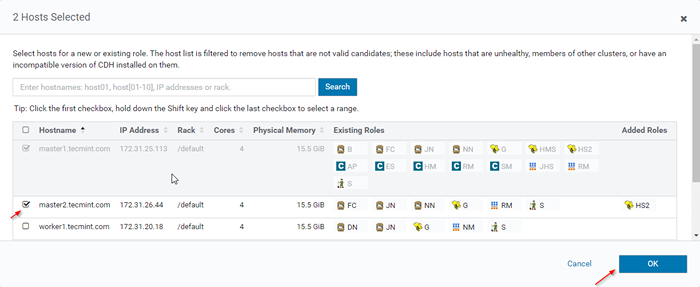 Elija servidor de host
Elija servidor de host 13. Una vez seleccionado el servidor, haga clic en 'Continuar'.
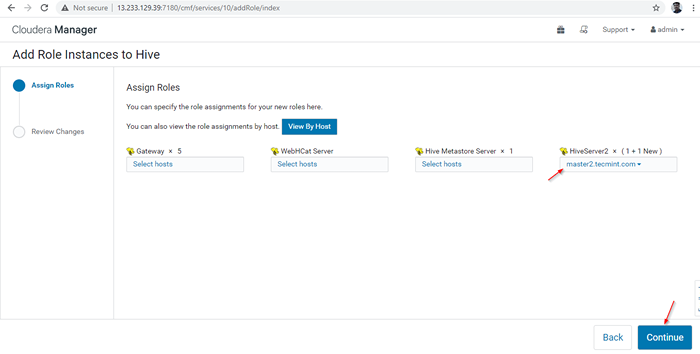 Servidor agregado
Servidor agregado 14. A Hiverserver2 se agregará al Instancias de colmena, necesitas comenzar yendo a Gerente de Cloudera -> Colmena -> Instancias -> (Seleccione Hiveserver2 agregado recién) -> Acción para seleccionado -> Comenzar.
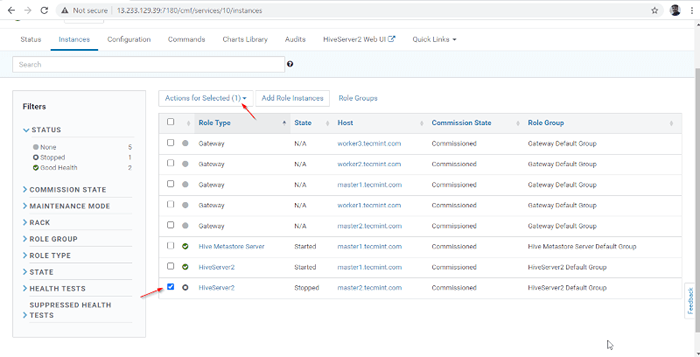 Elija Hive Server
Elija Hive Server 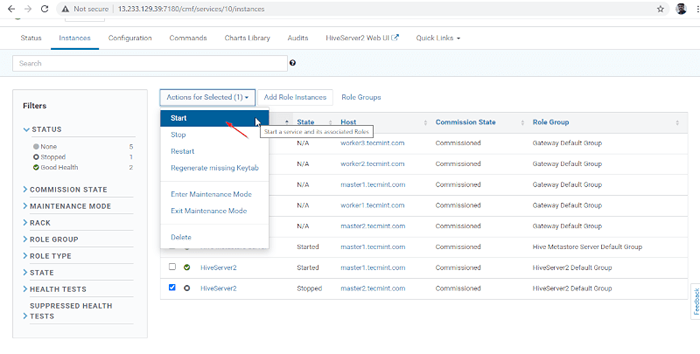 Iniciar servidor Hive
Iniciar servidor Hive 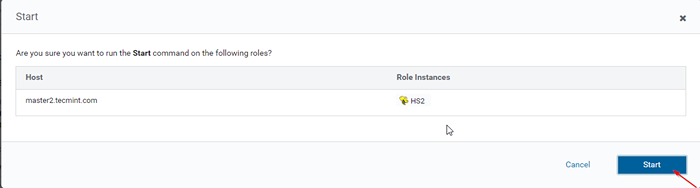 Inicie el servidor Hive
Inicie el servidor Hive 15. Una vez Hiveserver2 comenzó en maestro2, obtendrás el estado 'Finalizado'. Hacer clic Cerca.
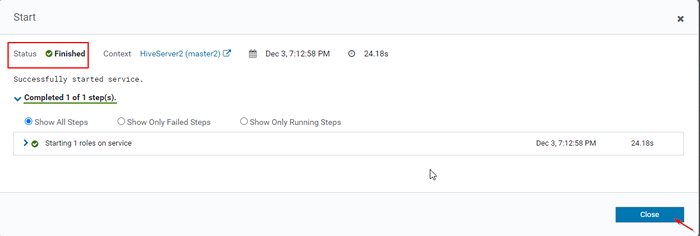 Estado: Finalizado
Estado: Finalizado dieciséis. Puedes ver, ambos Hiveserver2s estan corriendo.
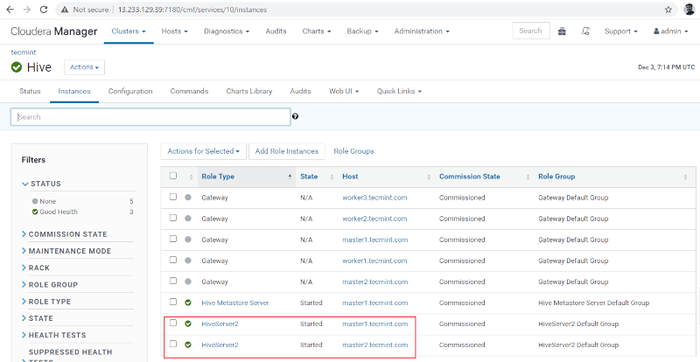 Verificar el estado de los servidores de colmena
Verificar el estado de los servidores de colmena Verificar la disponibilidad de colmena
Podemos conectar el Hiveserver2 a través de Beeline que es un cliente delgado y línea de comandos. Utiliza el controlador JDBC para establecer la conexión.
17. Iniciar sesión en el servidor donde Puerta de entrada a la colmena Esta corriendo.
[[correo electrónico protegido] ~] $ beeline
 Conéctese a Hiveserver2
Conéctese a Hiveserver2 18. Introducir el JDBC Cadena de conexión para conectar el Hiveserver2. A este respecto, el cadena Estamos mencionando el Hiverserver2 (maestro2) con su número de puerto predeterminado 10000. Esta cadena de conexión solo se conectará a la Hiveserver2 que se está ejecutando maestro2.
Beeline> !conectar "JDBC: Hive2: // Master1.tecmenta.com: 10000 "
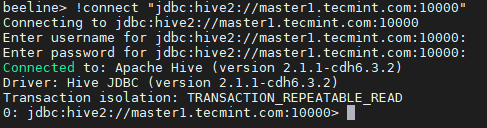 Cadena de conexión JDBC
Cadena de conexión JDBC 19. Ejecutar una consulta de muestra.
0: JDBC: Hive2: // Master1.tecmenta.com: 10000> Mostrar bases de datos;
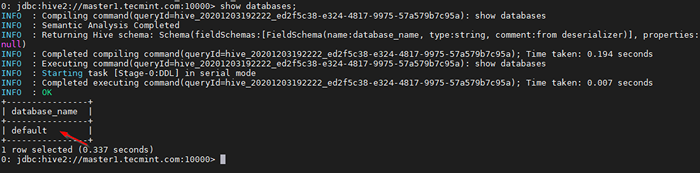 Ejecutar una consulta de muestra
Ejecutar una consulta de muestra Esta es la base de datos predeterminada que viene incorporada.
20. Use el siguiente comando a continuación para finalizar la sesión de colmena.
0: JDBC: Hive2: // Master1.tecmenta.com: 10000> !abandonar
 Dejar la sesión de la colmena
Dejar la sesión de la colmena 21. Puedes usar la misma forma de conectar Hiveserver2 que se ejecuta en maestro2.
Beeline> !conectar "JDBC: Hive2: // Master2.tecmenta.com: 10000 "
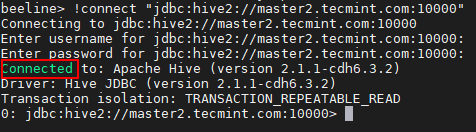 Conectarse al servidor Hive
Conectarse al servidor Hive 23. Podemos conectar el Hiveserver2 en Descubrimiento del chokeeper modo. En este método, no necesitamos mencionar el Hiveserver2 En la cadena de conexión en su lugar estamos usando Choque para descubrir el disponible Hiveserver2.
Aquí podemos usar un equilibrador de carga de terceros para equilibrar la carga entre las disponibles Hiverserver2. La siguiente configuración es necesaria para habilitar Modo de descubrimiento de Zookeeper yendo a Gerente de Cloudera -> Colmena -> Configuración.
 Habilitar el modo de descubrimiento de Zookeeper
Habilitar el modo de descubrimiento de Zookeeper 24. A continuación, busque la propiedad "Fragmento de configuración avanzada Hiveserver2"Y haga clic en el + Símbolo para agregar la propiedad a continuación.
Nombre: Hive.servidor2.apoyo.dinámica.servicio.Valor de descubrimiento: verdadera descripción:
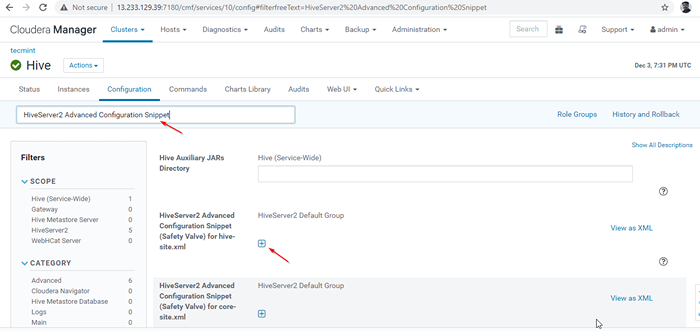 Fragmento de configuración avanzada Hiveserver2
Fragmento de configuración avanzada Hiveserver2 25. Una vez ingresado a la propiedad, haga clic ''Guardar cambios'.
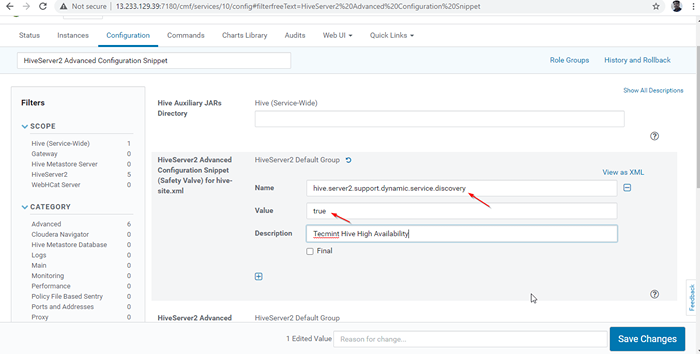 Agregar propiedad
Agregar propiedad 26. A medida que realizamos cambios en la configuración, debemos reiniciar los servicios afectados haciendo clic en el símbolo de color naranja para reiniciar los servicios.
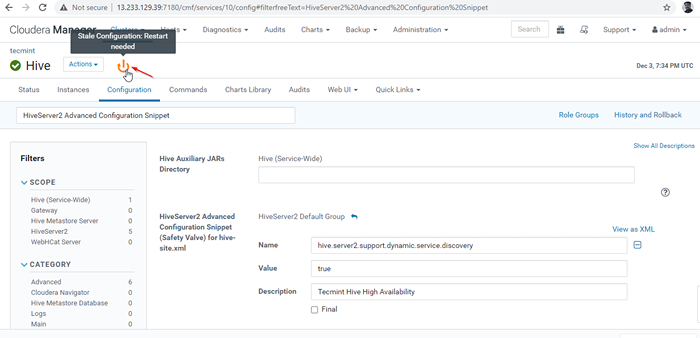 Reiniciar servicios
Reiniciar servicios 27. Haga clic 'Reiniciar rancio'Servicios.
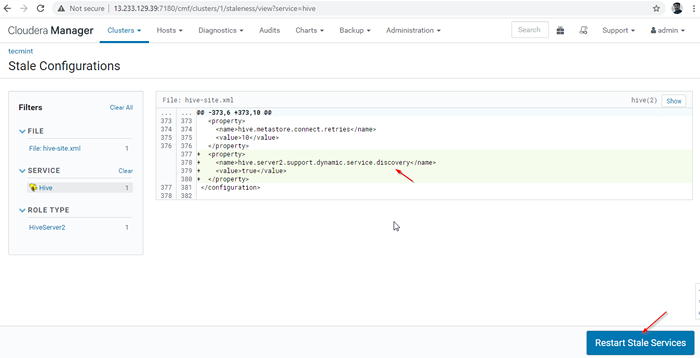 Reiniciar servicios rancios
Reiniciar servicios rancios 28. Hay dos opciones disponibles. Si el clúster está en producción en vivo, debemos preferir el reinicio de Rolling para minimizar la interrupción. Como estamos instalando recientemente, podemos elegir la segunda opción 'Volver a implementar la configuración del cliente', y hacer clic' 'Reiniciar ahora'.
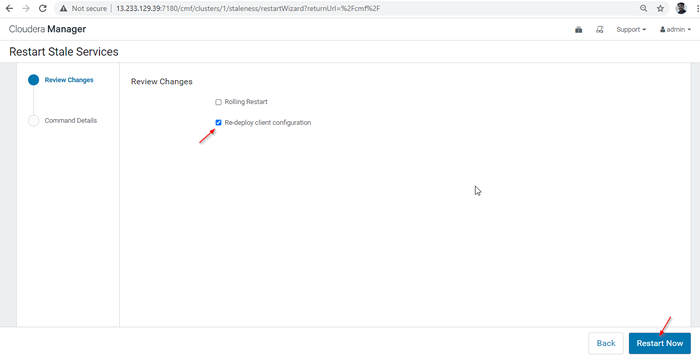 Volver a implementar la configuración del cliente
Volver a implementar la configuración del cliente 29. Una vez que el reinicio se haya completado con éxito, obtendrá el estado 'Finalizado'. Haga clic 'Finalizar'Para completar el proceso.
 Terminar el proceso
Terminar el proceso 30. Ahora conectaremos el Hiveserver2 usando Descubrimiento del chokeeper modo. En el JDBC conexión, la cadena necesitamos usar el Choque servidores con su número de puerto 2081. Recoja los servidores Zookeeper yendo a Gerente de Cloudera -> Choque -> Instancias -> (Anota los nombres de los servidores).
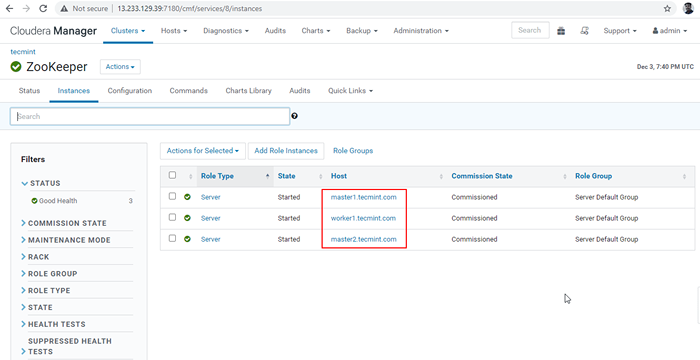 Servidores Zookeepers
Servidores Zookeepers Estos son los tres servidores que tienen Zookeeper, 2181 es el número de puerto.
maestro1.tecmenta.com: 2181 Master2.tecmenta.com: 2181 trabajador1.tecmenta.com: 2181
31. Ahora entra en línea recta.
[[correo electrónico protegido] ~] $ beeline
 Conectarse a Beeline
Conectarse a Beeline 32. Introducir el JDBC Cadena de conexión como se menciona a continuación. Tenemos que mencionar el Modo de descubrimiento de servicio y Espacio de nombres de chokeeper. 'Hiveserver2'es el espacio de nombres predeterminado de Hiveserver2.
Beeline>!conectar "JDBC: Hive2: // Master1.tecmenta.com: 2181, maestro2.tecmenta.com: 2181, trabajador1.tecmenta.com: 2181/; ServiceScoveryMode = ZOOKEEPER; ZOOKEEPERNAMESPACE = HIVISERVER2 "
 Ingrese la cadena de conexión JDBC
Ingrese la cadena de conexión JDBC 33. Ahora la sesión está conectada a Hiveserver2 que se ejecuta en maestro1. Ejecute una consulta de muestra para validar. Use el siguiente comando a continuación para crear una base de datos.
0: JDBC: Hive2: // Master1.tecmenta.com: 2181, mast> Crear base de datos TECMINT;
 Crear base de datos
Crear base de datos 34. Use el comando a continuación para enumerar la base de datos.
0: JDBC: Hive2: // Master1.tecmenta.com: 2181, Mast> Mostrar bases de datos;
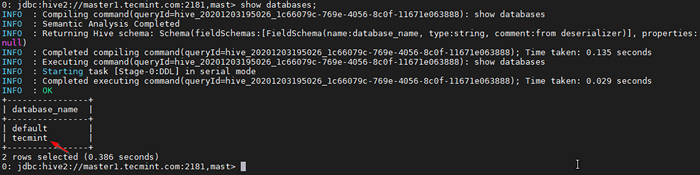 Base de datos
Base de datos 35. Ahora validaremos la alta disponibilidad en Modo de descubrimiento de Zookeeper. Ir a Gerente de Cloudera y detener el Hiveserver2 en maestro1 que hemos probado anteriormente.
Gerente de Cloudera -> Colmena -> Instancias -> (Seleccionar Hiveserver2 en maestro1) -> Acción para seleccionado -> Detener.
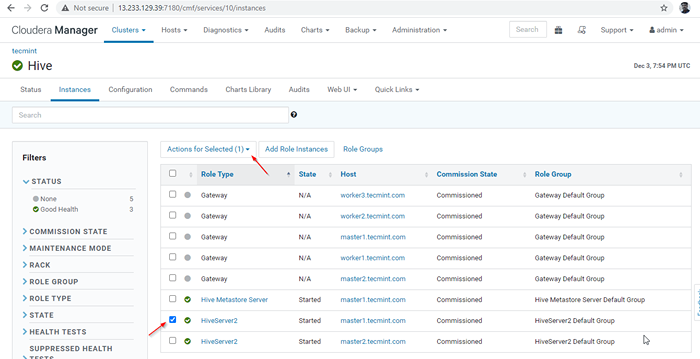 Elija Hive Server
Elija Hive Server 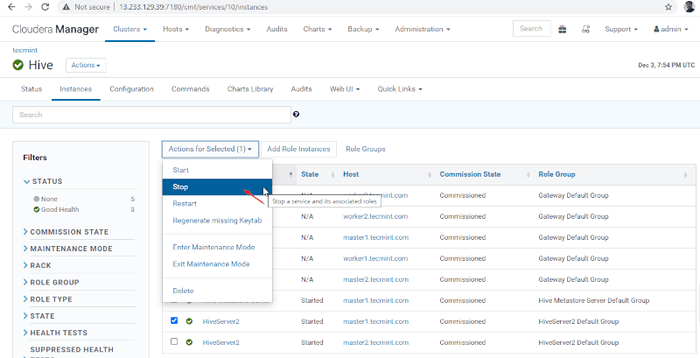 Stop Hive Server
Stop Hive Server 36. Haga clic en el 'Detener'. Una vez detenido, obtendrá el estado 'Finalizado'. Verificar el Hiveserver2 en maestro1 navegando hacia Colmena -> Instancias.
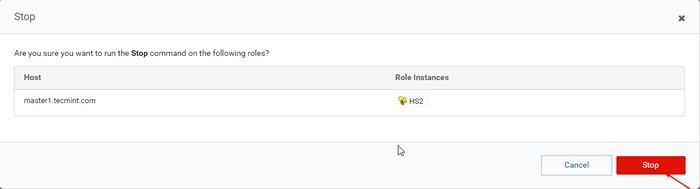 Stop Hive Server
Stop Hive Server 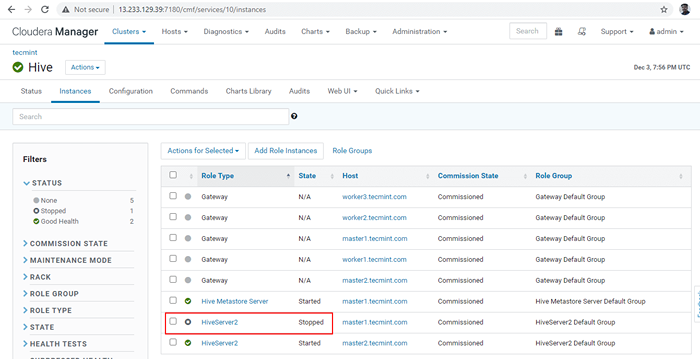 Verificar el servidor Hive
Verificar el servidor Hive 37. Entrar en el línea recta y conecte el Hiveserver2 Usando lo mismo JDBC Cadena de conexión con Modo de descubrimiento de Zookeeper Como lo hicimos en los pasos anteriores.
[[correo electrónico protegido] ~] $ beeline beeline>!conectar "JDBC: Hive2: // Master1.tecmenta.com: 2181, maestro2.tecmenta.com: 2181, trabajador1.tecmenta.com: 2181/; ServiceScoveryMode = ZOOKEEPER; ZOOKEEPERNAMESPACE = HIVISERVER2 "
 Conecte el Hiveserver2
Conecte el Hiveserver2 Ahora estarás conectado con Hiveserver2 que se ejecuta en maestro2.
38. Validar con una consulta de muestra.
0: JDBC: Hive2: // Master1.tecmenta.com: 2181, Mast> Mostrar bases de datos;
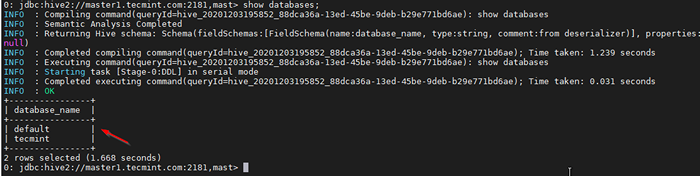 Validar la consulta de muestra
Validar la consulta de muestra Conclusión
En este artículo, hemos pasado por los pasos detallados para tener el Almacén de datos de colmena modelo en nuestro Grupo con Alta disponibilidad. En un entorno de producción en tiempo real, más de tres Hiveserver2 se colocará con Modo de descubrimiento de Zookeeper activado.
Aquí, todo el Hiveserver2's se están registrando con Choque bajo un común Espacio de nombres. Zookeeper dinámicamente Descubre el disponible Hiveserver2 y establece la sesión de colmena.
- « Cómo instalar VMware Workstation 16 Pro en sistemas Linux
- Cómo instalar un clúster de Kubernetes en Centos 8 »