

Cómo instalar Apache Hadoop en Ubuntu 22.04

- 3014
- 753
- Claudia Baca
Comprender los datos no estructurados y analizar cantidades masivas de datos es un juego de pelota diferente hoy en día. Y así, las empresas han recurrido a Apache Hadoop y otras tecnologías relacionadas para administrar sus datos no estructurados de manera más eficiente. No solo las empresas sino también las personas utilizan Apache Hadoop para diversos fines, como analizar grandes conjuntos de datos o crear un sitio web que pueda procesar consultas de los usuarios. Sin embargo, instalar Apache Hadoop en Ubuntu puede parecer una tarea difícil para los usuarios nuevos en el mundo de los servidores Linux. Afortunadamente, no necesita ser un administrador de sistemas experimentado para instalar Apache Hadoop en Ubuntu.
La siguiente guía de instalación paso a paso lo hará a través de todo el proceso desde la descarga del software hasta configurar el servidor con facilidad. En este artículo, explicaremos cómo instalar Apache Hadoop en Ubuntu 22.04 Sistema LTS. Esto también se puede usar para otras versiones de Ubuntu.
Paso 1: Instale el kit de desarrollo Java
Java es un componente necesario de Apache Hadoop, por lo que debe descargar e instalar un kit de desarrollo Java en todos los nodos en su red donde se instalará Hadoop. Puedes descargar el jre o jdk. Si solo está buscando ejecutar Hadoop, entonces JRE es suficiente, pero si desea crear aplicaciones que se ejecuten en Hadoop, entonces deberá instalar el JDK. La última versión de Java que admite Hadoop es Java 8 y 11. Puede verificar esto en el sitio web de Apache y descargar la versión relevante de Java dependiendo de su sistema operativo.
- Los repositorios de Ubuntu predeterminados contienen Java 8 y Java 11 ambos. Use el siguiente comando para instalarlo.
Sudo Apt Update && sudo apt install OpenJDK-11-JDK - Una vez que lo haya instalado con éxito, consulte la versión actual de Java:
Java -versión Verifique la versión de Java
Verifique la versión de Java - Puede encontrar la ubicación del directorio Java_Home ejecutando el siguiente comando. Que se requerirá más tarde en este artículo.
dirname $ (dirname $ (readlink -f $ (que java))) Verifique la ubicación de Java_Home
Verifique la ubicación de Java_Home
Paso 2: Crear usuario para Hadoop
Todos los componentes de Hadoop se ejecutarán como el usuario que crea para Apache Hadoop, y el usuario también se utilizará para iniciar sesión en la interfaz web de Hadoop. Puede crear una nueva cuenta de usuario con el comando "sudo" o puede crear una cuenta de usuario con permisos "root". La cuenta de usuario con permisos raíz es más segura, pero puede que no sea tan conveniente para los usuarios que no están familiarizados con la línea de comandos.
- Ejecute el siguiente comando para crear un nuevo usuario con el nombre "Hadoop":
Adduser de sudo Hadoop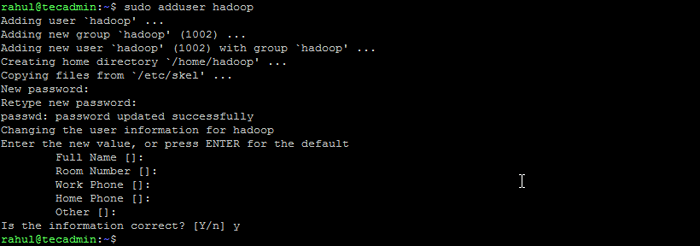 Crear usuario de Hadoop
Crear usuario de Hadoop - Cambie al usuario de Hadoop recién creado:
Su - Hadoop - Ahora configure el acceso SSH sin contraseña para el usuario de Hadoop recién creado. Genere un KeyPair SSH primero:
ssh -keygen -t RSA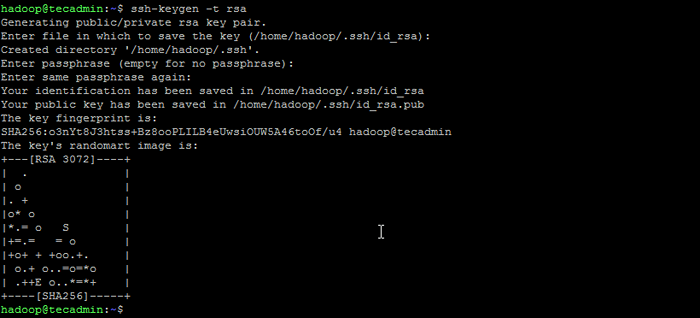 Generar el par de claves SSH
Generar el par de claves SSH - Copie la clave pública generada al archivo de clave autorizado y establezca los permisos adecuados:
gato ~/.ssh/id_rsa.Pub >> ~/.ssh/autorized_keysChmod 640 ~/.ssh/autorized_keys - Ahora intente ssh al localhost.
ssh localhostSe le pedirá que autentique hosts agregando claves RSA a los hosts conocidos. Escriba sí y presione Enter para autenticar el LocalHost:
 Conectar ssh a localhost
Conectar ssh a localhost
Paso 3: Instale Hadoop en Ubuntu
Una vez que haya instalado Java, puede descargar Apache Hadoop y todos sus componentes relacionados, incluidos Hive, Pig, Sqoop, etc. Puede encontrar la última versión en la página de descarga oficial de Hadoop. Asegúrese de descargar el archivo binario (no la fuente).
- Use el siguiente comando para descargar Hadoop 3.3.4:
wget https: // dlcdn.apache.org/Hadoop/Common/Hadoop-3.3.4/Hadoop-3.3.4.alquitrán.GZ - Una vez que haya descargado el archivo, puede descomponerlo a una carpeta en su disco duro.
tar xzf hadoop-3.3.4.alquitrán.GZ - Cambie el nombre de la carpeta extraída para eliminar la información de la versión. Este es un paso opcional, pero si no desea cambiar el nombre, ajuste las rutas de configuración restantes.
MV Hadoop-3.3.4 Hadoop - A continuación, deberá configurar las variables de entorno Hadoop y Java en su sistema. Abra el ~/.archivo bashrc en su editor de texto favorito:
nano ~/.bashrcAgregue las líneas a continuación al archivo. Puedes encontrar la ubicación java_home ejecutando
Exportar java_home =/usr/lib/jvm/java-11-openjdk-amd64 exportar hadoop_home =/home/hadoop/hadoop exportoop_install = $ hadoop_home exportoop_mapred_home = $ hadoop_home exportoop_comommon_home = hadoop_home export_hdefs_home = $ hadoop_home Hadoop_home exportoop_common_lib_native_dir = $ hadoop_home/lib/native export rath = $ ruta: $ hadoop_home/sbin: $ hadoop_home/bin exportoop_opts = "-djava.biblioteca.ruta = $ hadoop_home/lib/nativo "dirname $ (dirname $ (readlink -f $ (que java)))comando en la terminal.12345678910 export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64export HADOOP_HOME=/home/hadoop/hadoopexport HADOOP_INSTALL=$HADOOP_HOMEexport HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport HADOOP_YARN_HOME=$HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/ Lib/nativeExport ruta = $ ruta: $ hadoop_home/sbin: $ hadoop_home/binexport hadoop_opts = "-djava.biblioteca.ruta = $ hadoop_home/lib/nativo " Guarde el archivo y cierre.
- Cargue la configuración anterior en el entorno actual.
fuente ~/.bashrc - También necesitas configurar Java_home en hadoop-env.mierda archivo. Edite el archivo variable de entorno Hadoop en el editor de texto:
nano $ hadoop_home/etc/hadoop/hadoop-envv.mierdaBusque el "Exportar java_home" y configúrelo con el valor que se encuentra en el paso 1. Vea la siguiente captura de pantalla:
 Establecer java_home
Establecer java_homeGuarde el archivo y cierre.
Paso 4: Configuración de Hadoop
Lo siguiente es configurar los archivos de configuración de Hadoop disponibles en el directorio ETC ETC.
- Primero, necesitará crear el namenode y datanode Directorios dentro del Directorio de inicio del usuario de Hadoop. Ejecute el siguiente comando para crear ambos directorios:
mkdir -p ~/hadoopdata/hdfs/nameNode, dataNode - A continuación, edite el sitio de núcleo.xml Archivo y actualización con el nombre de host de su sistema:
nano $ hadoop_home/etc/hadoop/nore-site.xmlCambie el siguiente nombre según su nombre de host del sistema:
FS.defaultfs hdfs: // localhost: 9000123456 FS.defaultfs hdfs: // localhost: 9000 Guarde y cierre el archivo.
- Entonces, edite el sitio HDFS.xml archivo:
nano $ hadoop_home/etc/hadoop/hdfs-site.xmlCambie las rutas del directorio NameNode y DataNode como se muestra a continuación:
DFS.Replicación 1 DFS.nombre.Archivo Dir: /// home/hadoop/hadoopdata/hdfs/nameNode DFS.datos.archivo dir: /// home/hadoop/hadoopdata/hdfs/datanode12345678910111213141516 DFS.Replicación 1 DFS.nombre.Archivo Dir: /// home/hadoop/hadoopdata/hdfs/nameNode DFS.datos.archivo dir: /// home/hadoop/hadoopdata/hdfs/datanode Guarde y cierre el archivo.
- Entonces, edite el sitio de mapred.xml archivo:
nano $ hadoop_home/etc/hadoop/mapred-site.xmlHacer los siguientes cambios:
Mapa reducido.estructura.hilo de nombre123456 Mapa reducido.estructura.hilo de nombre Guarde y cierre el archivo.
- Entonces, edite el hilo.xml archivo:
nano $ hadoop_home/etc/hadoop/hilo-sitio.xmlHacer los siguientes cambios:
hilo.nodo.Aux-Services MapReduce_Shuffle123456 hilo.nodo.Aux-Services MapReduce_Shuffle Guarde el archivo y cierre.
Paso 5: Inicie Hadoop Cluster
Antes de comenzar el clúster de Hadoop. Deberá formatear el NameNode como usuario de Hadoop.
- Ejecute el siguiente comando para formatear el hadoop namenode:
HDFS namenode -FormatUna vez que el directorio de NameNode se formatea correctamente con el sistema de archivos HDFS, verá el mensaje "El directorio de almacenamiento/home/hadoop/hadoopdata/hdfs/namenode se ha formateado correctamente".
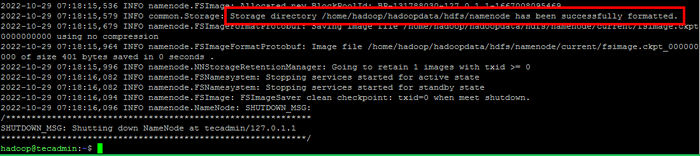 Formatear namenode
Formatear namenode - Luego comience el clúster Hadoop con el siguiente comando.
inicio.mierda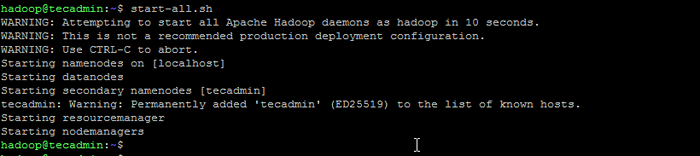 Iniciar servicios de Hadoop
Iniciar servicios de Hadoop - Una vez que comenzaron todos los servicios, puede acceder al Hadoop en: http: // localhost: 9870

- Y la página de la aplicación Hadoop está disponible en http: // localhost: 8088

Conclusión
La instalación de Apache Hadoop en Ubuntu puede ser una tarea difícil para los novatos, especialmente si solo siguen las instrucciones en la documentación. Afortunadamente, este artículo proporciona una guía paso a paso que lo ayudará a instalar Apache Hadoop en Ubuntu con facilidad. Todo lo que tiene que hacer es seguir las instrucciones enumeradas en este artículo, y puede estar seguro de que su instalación de Hadoop estará en funcionamiento en poco tiempo.