

Cómo instalar el clúster Elasticsearch (múltiple nodo) en CentOS/RHEL, Ubuntu y Debian

- 2539
- 439
- Carmen Casillas
Elasticsearch es un código abierto flexible y potente, búsqueda distribuida en tiempo real y motor analítico. Usando un conjunto simple de API, proporciona la capacidad de la búsqueda de texto completo. La búsqueda elástica está disponible gratuitamente bajo la licencia Apache 2, que proporciona la mayor flexibilidad.
Este artículo lo ayudará a configurar el clúster de nodos múltiples Elasticsearch en CentOS, RHEL, Ubuntu y Debian Systems. En ElasticSearch, el clúster de nodos múltiples solo está configurando múltiples clústeres de nodo único con el mismo nombre de clúster en la misma red.
Paisaje de red
Tenemos tres servidores con los siguientes IP y nombres de host. Todos los servidores se ejecutan en la misma LAN y tienen acceso completo al servidor del otro usando IP y nombre de host ambos.
192.168.10.101 nodo_1 192.168.10.102 Node_2 192.168.10.103 nodo_3
Verificar Java (todos los nodos)
Java es el requisito principal para instalar Elasticsearch. Así que asegúrese de tener Java instalado en todos los nodos.
# Java -version Java versión "1.8.0_31 "Java (TM) SE Runtime Entorno (Build 1.8.0_31-B13) Java Hotspot (TM) VM de 64 bits (Build 25.31-B07, modo mixto)
Si no tiene Java instalado en ningún sistema de nodo, use uno de los siguientes enlaces para instalarlo primero.
Instale Java 8 en CentOS/RHEL 7/6/5
Instale Java 8 en Ubuntu
Descargar Elasticsearch (todos los nodos)
Ahora descargue el último archivo de elasticsearch en todos los sistemas de nodo desde su página de descarga oficial. En el momento de la última actualización de este artículo Elasticsearch 1.4.2 La versión es la última versión disponible para descargar. Use el siguiente comando para descargar Elasticsearch 1.4.2.
$ wget https: // descargar.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.4.2.alquitrán.GZ
Ahora extraiga Elasticsearch en todos los sistemas de nodo.
$ tar xzf elasticsearch-1.4.2.alquitrán.GZ
Configurar elasticsearch
Ahora necesitamos configurar ElasticSearch en todos los sistemas de nodo. Elasticsearch utiliza "Elasticsearch" como nombre de clúster predeterminado. Recomendamos cambiarlo según su conversación de nombres.
$ MV Elasticsearch-1.4.2/usr/share/elasticsearch $ cd/usr/share/elasticsearch
Para cambiar el clúster llamado editar config/elasticsearch.YML Archivo en cada nodo y actualizar los siguientes valores. Los nombres de los nodos se generan dinámicamente, pero para mantener un nombre de nombre fijo, cambialo también.
En nodo_1
Editar la configuración del clúster Elasticsearch en Node_1 (192.168.10.101) Sistema.
$ vim config/elasticsearch.YML
grupo.Nombre: nodo tecadmincluster.Nombre: "Node_1"
En node_2
Editar configuración de clúster Elasticsearch en Node_2 (192.168.10.102) Sistema.
$ vim config/elasticsearch.YML
grupo.Nombre: nodo tecadmincluster.Nombre: "Node_2"
En node_3
Editar configuración de clúster Elasticsearch en Node_3 (192.168.10.103) Sistema.
$ vim config/elasticsearch.YML
grupo.Nombre: nodo tecadmincluster.Nombre: "Node_3"
Instalar el complemento de la cabeza de elastics (todos los nodos)
Elasticsearch-Head es una parte delantera web para navegar e interactuar con un clúster de búsqueda elástica. Use el siguiente comando para instalar este complemento en todos los sistemas de nodo.
$ bin/plugin --stall mobz/elasticsearch-head
Iniciar clúster de elasticsearch (todos los nodos)
Como se ha completado la configuración del clúster Elasticsearch. Deje inicio el clúster de elasticsearch usando el siguiente comando en todos los nodos.
ps ./bin/elasticsearch &
Por defecto, Elasticserch escuche en el puerto 9200 y 9300. Así que conéctate a Nodo_1 En el puerto 9200, como la siguiente URL, verá los tres nodos en su clúster.
http: // node_1: 9200/_plugin/head/
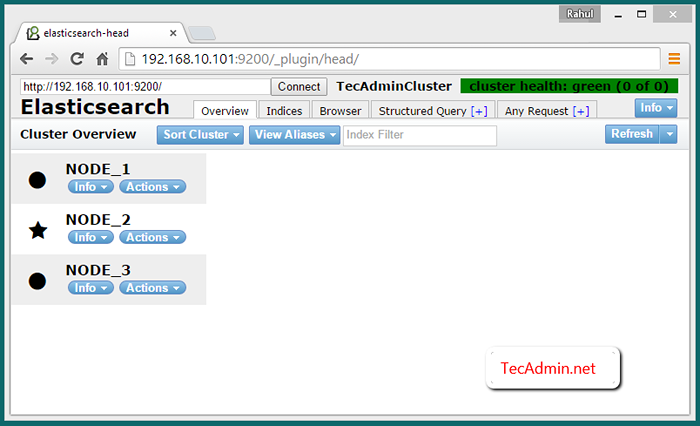
Verificar el clúster de nodos múltiples
Para verificar que el clúster funcione correctamente. Inserte algunos datos en un nodo y si los mismos datos están disponibles en otros nodos, significa que el clúster funciona correctamente.
Insertar datos en Node_1
Para verificar el clúster, cree un cubo en Nodo_1 y agregar algunos datos.
$ curl -xput http: // node_1: 9200/mybucket $ curl -xput 'http: // node_1: 9200/mybucket/user/rahul' -d '"nombre": "rahul kumar"'
$ curl -xput 'http: // node_1: 9200/mybucket/post/1' -d '"user": "rahul", "post -date": "01-16-2015", "cuerpo": "Agregar datos en Elasticsearch Cluster "," Título ":" Test de clúster Elasticsearch " '
Buscar datos en todos los nodos
Ahora busque los mismos datos de Nodo_2 y Nodo_3 y verifique si los mismos datos se replican a otros nodos del clúster. Según los comandos anteriores, hemos creado un usuario llamado Rahul y agregamos algunos datos allí. Entonces, use los siguientes comandos para buscar datos asociados con el usuario Rahul.
$ curl 'http: // node_1: 9200/mybucket/post/_search?Q = Usuario: Rahul & Pretty = True '$ curl' http: // node_2: 9200/mybucket/post/_search?Q = Usuario: Rahul & Pretty = True '$ curl' http: // node_3: 9200/mybucket/post/_search?Q = Usuario: Rahul & Pretty = True '
y obtendrá resultados algo como a continuación para todos los comandos anteriores.
"Tomado": 69, "Timed_out": False, "_shards": "Total": 5, "Exitoso": 5, "Falló": 0, "Hits": "Total": 1, "Max_Score ": 1.0, "Hits": ["_index": "mybucket", "_type": "post", "_id": "1", "_score": 1.0, "_source": "usuario": "rahul", "post-date": "16-16-2015", "cuerpo": "Agregar datos en elasticsearch cluster", "title": "Elasticsearch cluster test" ]
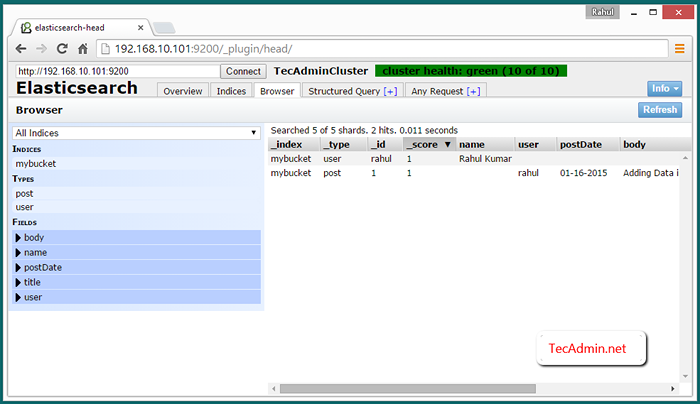
Ver datos de clúster en el navegador web
Para ver los datos sobre Elasticsearch Access del clúster del complemento Elasticsearch-Head utilizando uno de la IP de clúster a continuación URL. Luego haga clic en Navegador pestaña.
http: // node_1: 9200/_plugin/head/
- « Cómo usar el comando SystemCTL para administrar los servicios Systemd
- Agregar un repositorio adicional EPEL y REMI en un sistema basado en RHEL »