

Cómo realizar solicitudes HTTP con Python - Parte 1 La biblioteca estándar

- 4479
- 257
- Sra. Lorena Sedillo
HTTP es el protocolo utilizado por la World Wide Web, por eso ser capaz de interactuar con TI mediante programación es esencial: raspar una página web, comunicarse con una API de servicio o incluso descargar un archivo, son tareas basadas en esta interacción. Python hace que tales operaciones sean muy fáciles: algunas funciones útiles ya se proporcionan en la biblioteca estándar, y para tareas más complejas es posible (e incluso se recomienda) usar el externo peticiones módulo. En este primer artículo de la serie nos centraremos en los módulos incorporados. Usaremos Python3 y trabajaremos principalmente dentro de la carcasa interactiva de Python: las bibliotecas necesarias se importarán solo una vez para evitar repeticiones.
En este tutorial aprenderás:
- Cómo realizar solicitudes HTTP con Python3 y Urllib.biblioteca de solicitud
- Cómo trabajar con las respuestas del servidor
- Cómo descargar un archivo usando las funciones de Urlopen o Urlretieve
Solicitud HTTP con Python - PT. I: la biblioteca estándar
Requisitos y convenciones de software utilizados
| Categoría | Requisitos, convenciones o versión de software utilizada |
|---|---|
| Sistema | INDEPENDO DEL OS |
| Software | Python3 |
| Otro |
|
| Convenciones | # - requiere que los comandos de Linux dados se ejecuten con privilegios raíz directamente como un usuario raíz o mediante el uso de sudo dominiops - Requiere que los comandos de Linux dados se ejecuten como un usuario regular no privilegiado |
Realización de solicitudes con la biblioteca estándar
Comencemos con un muy fácil CONSEGUIR pedido. El verbo get http se usa para recuperar datos de un recurso. Al realizar este tipo de solicitudes, es posible especificar algunos parámetros en las variables de formulario: esas variables, expresadas como pares de valor clave, forman un cadena de consulta que se "adjunta" al Url del recurso. Una solicitud de obtención siempre debe ser idempotente (Esto significa que el resultado de la solicitud debe ser independiente del número de veces que se realiza) y nunca debe usarse para cambiar un estado. Realizar solicitudes con Python es realmente fácil. En aras de este tutorial, aprovecharemos la llamada de la API de la NASA abierta que recuperemos la llamada "imagen del día":
>>> de Urllib.Solicitar la importación de Urlopen >>> con Urlopen ("https: // API.NASA.Gov/Planetary/APOD?api_key = demo_key ") como respuesta: ... respuesta_content = respuesta.leer() Lo primero que hicimos fue importar el urgente función desde el urllib.pedido Biblioteca: esta función devuelve un http.cliente.Httpresponse objeto que tiene algunos métodos muy útiles. Usamos la función dentro de un con declaración porque el Httpresponse El objeto admite el gestión de contexto Protocolo: los recursos se cierran inmediatamente después de ejecutar la declaración "con", incluso si un excepción es elevado.
El leer Método que utilizamos en el ejemplo anterior Devuelve el cuerpo del objeto de respuesta como un bytes y opcionalmente toma un argumento que representa la cantidad de bytes para leer (veremos más tarde cómo esto es importante en algunos casos, especialmente al descargar archivos grandes). Si se omite este argumento, el cuerpo de la respuesta se lee en su totalidad.
En este punto tenemos el cuerpo de la respuesta como objeto bytes, referenciado por el respuesta_content variable. Es posible que queramos transformarlo en otra cosa. Para convertirlo en una cadena, por ejemplo, usamos el descodificar método, proporcionando el tipo de codificación como argumento, típicamente:
>>> respuesta_content.Decode ('UTF-8') En el ejemplo anterior usamos el UTF-8 codificación. La llamada API que utilizamos en el ejemplo, sin embargo, devuelve una respuesta en Json formato, por lo tanto, queremos procesarlo con la ayuda del json módulo:
>>> Importar JSON JSON_RESPONDE = JSON.Cargas (Respuesta_Content) El json.cargas El método deserializa un cadena, a bytes o bytearray instancia que contiene un documento JSON en un objeto Python. El resultado de llamar a la función, en este caso, es un diccionario:
>>> de PPRint import PPrint >>> PPrint (JSON_RESPONSE) 'Date': '2019-04-14', 'Explicación': 'Siéntate y mira dos agujeros negros fusionar. Inspirado en la "primera detección directa de ondas gravitacionales en 2015, este" video de simulación se reproduce en cámara lenta, pero tomaría alrededor de un tercio de segundo si se ejecuta en tiempo real. Ubicado en una etapa cósmica de los agujeros negros se plantean frente a estrellas, gas y "polvo. Su gravedad extrema lente la luz de los que se detrás de ellos '' en los anillos de Einstein mientras se acercan y finalmente se fusionan '' en uno. Las ondas gravitacionales invisibles '' generadas como los objetos masivos que se unen rápidamente hacen que la '' imagen visible se extiende y se derrita tanto dentro como fuera de los '' anillos de Einstein incluso después de que los agujeros negros se hayan fusionado. Apodado '' GW150914, las ondas gravitacionales detectadas por LIGO son '' consistentes con la fusión de 36 y 31 agujeros de masa solar negra '' a una distancia de 1.3 mil millones de años luz. El último agujero negro, '' final tiene 63 veces la masa del sol, con las '3 masas solares restantes convertidas en energía en' 'ondas gravitacionales. Desde entonces, los observatorios de ondas gravitacionales de Ligo y Virgo han informado varias '' más detecciones de sistemas masivos fusionados, mientras que la semana pasada el '' Event Horizon Telescope informó la primera imagen de escala de horizonte '' de un agujero negro de un agujero negro de un agujero negro.',' Media_Type ':' Video ',' Service_Version ':' V1 ',' Título ':' Simulación: Dos agujeros negros Fusion ',' Url ':' https: // www.YouTube.com/incrustar/i_88s8dwbcu?rel = 0 ' Como alternativa también podríamos usar el json_load función (observe la "S" de Tailing Falting). La función acepta un como archivo objeto como argumento: Esto significa que podemos usarlo directamente en el Httpresponse objeto:
>>> con Urlopen ("https: // API.NASA.Gov/Planetary/APOD?api_key = demo_key ") como respuesta: ... JSON_RESPONSE = JSON.Carga (respuesta) Leyendo los encabezados de respuesta
Otro método muy útil utilizable en el Httpresponse El objeto es Getaders. Este método devuelve el encabezado de la respuesta como una variedad de tuplas. Cada tupla contiene un parámetro de encabezado y su valor correspondiente:
>>> PPRINT (respuesta.GetHeaders ()) [('servidor', 'OpenResty'), ('Date', 'Sun, 14 de abril de 2019 10:08:48 GMT'), ('Content-type', 'Application/Json'), (( 'Content-longitud', '1370'), ('Conexión', 'Cerrar'), ('Vary', 'Aceptar-Ending'), ('X-ratelimit-limit', '40'), ('x -Ratelimit-Remining ',' 37 '), (' vía ',' 1.1 Vegur, http/1.1 api-umbrella (apachetrafficserver [cmssf]) '), (' edad ',' 1 '), (' x-cache ',' fish '), (' access-confontrol-allow-origin ','*') , ('Strict-Transport-Security', 'Max-Age = 31536000; Preload')]] Puedes notar, entre los demás, el Tipo de contenido parámetro, que, como dijimos anteriormente, es Aplicación/JSON. Si queremos recuperar solo un parámetro específico, podemos usar el getader Método en su lugar, pasar el nombre del parámetro como argumento:
>>> Respuesta.GetHeader ('Content-type') 'Application/JSON' Obtener el estado de la respuesta
Obtener el código de estado y frase de la razón devuelto por el servidor después de una solicitud HTTP también es muy fácil: todo lo que tenemos que hacer es acceder a estado y razón propiedades del Httpresponse objeto:
>>> Respuesta.Estado 200 >>> Respuesta.razón 'ok' Incluyendo variables en la solicitud GET
La URL de la solicitud que enviamos anteriormente contenía solo una variable: Clave API, y su valor era "Demo_key". Si queremos pasar múltiples variables, en lugar de unirlas a la URL manualmente, podemos proporcionarlas y sus valores asociados como pares de valor clave de un diccionario de Python (o como una secuencia de tuplas de dos elementos); Este diccionario se pasará al urllib.analizar gramaticalmente.urlencode método, que construirá y devolverá el cadena de consulta. La llamada API que utilizamos anteriormente, permítanos especificar una variable opcional de "fecha" para recuperar la imagen asociada con un día específico. Así es como podríamos proceder:
>>> de Urllib.PARSE IMPORT URLENCODE >>> QUERY_PARAMS = ..."API_KEY": "Demo_Key", ..."Fecha": "2019-04-11" >>> QUIERY_STRING = URLENCODE (QUERY_PARAMS) >>> QUERY_STRING 'API_KEY = Demo_Key & Date = 2019-04-11' Primero definimos cada variable y su valor correspondiente como pares de valor clave de un diccionario, que pasamos dicho diccionario como un argumento al urlencode función, que devolvió una cadena de consulta formateada. Ahora, al enviar la solicitud, todo lo que tenemos que hacer es adjuntarla a la URL:
>>> url = "?".unirse (["https: // API.NASA.Gov/Planetary/Apod ", Query_String])
Si enviamos la solicitud usando la URL anterior, obtenemos una respuesta diferente y una imagen diferente:
'date': '2019-04-11', 'explicación': '¿Cómo se ve un agujero negro?? Para averiguarlo, la radio "telescopios de alrededor de la tierra observaciones coordinadas de" agujeros negros con los horizontes de eventos más grandes conocidos en el "cielo. Solo, los agujeros negros son solo negros, pero se sabe que estos atractores de estos monstruos "están rodeados de gas brillante. La "primera imagen se lanzó ayer y resolvió el área" alrededor del agujero negro en el centro de Galaxy M87 en una escala "debajo de lo esperado para su horizonte de eventos. En la foto, la "región central oscura no es el horizonte de eventos, sino la" sombra del "agujero negro, la región central del gas emisor" "oscurecido por la gravedad del agujero negro central. El tamaño y la "'forma de la sombra están determinados por gas brillante cerca del" horizonte de eventos, por fuertes desviaciones de lente gravitacional' ", y por el giro del agujero negro. Al resolver la "Shadow, el Telescopio Horizon Horizon (EHT) de este agujero negro, la evidencia reforzada" de que la gravedad de Einstein funciona incluso en regiones extremas, y "'dio evidencia clara de que M87 tiene un agujero negro giratorio" de aproximadamente 6 mil millones de masas solares solares. El EHT no se realiza: "Las observaciones futuras estarán orientadas a una resolución aún más alta", un mejor seguimiento de la variabilidad y explorar la "vecindad inmediata del agujero negro en el centro de nuestra" Vía Láctea Milky.',' hdurl ':' https: // apod.NASA.Gov/Apod/Image/1904/M87BH_EHT_2629.jpg ',' Media_Type ':' Image ',' Service_Version ':' V1 ',' Title ':' First Horizon-Scale de un agujero negro ',' url ':' https: // apod.NASA.Gov/Apod/Image/1904/M87BH_EHT_960.jpg '
En caso de que no se haya dado cuenta, la URL de la imagen devuelta apunta a la primera imagen recientemente revelada de un agujero negro:
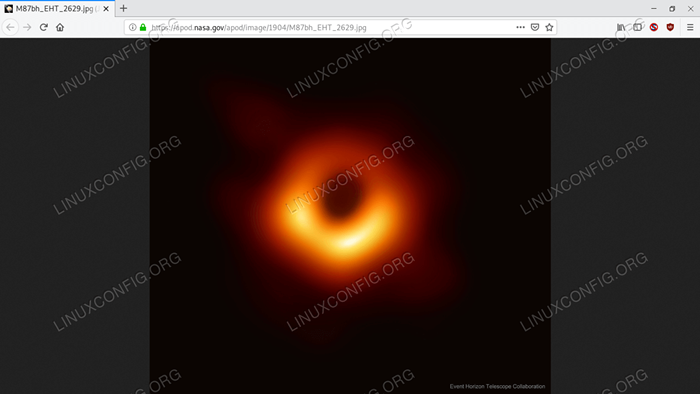
La imagen devuelta por la llamada API: la primera imagen de un agujero negro
Enviar una solicitud de publicación
Enviar una solicitud de publicación, con variables 'contenidas' dentro del cuerpo de solicitud, utilizando la biblioteca estándar, requiere pasos adicionales. En primer lugar, como lo hicimos antes, construimos los datos postales en forma de un diccionario:
>>> data = ... "Variable1": "Value1", ... "Variable2": "Value2" ... Después de construir nuestro diccionario, queremos usar el urlencode función como lo hicimos antes, y codifica adicionalmente la cadena resultante en ascii:
>>> post_data = urlencode (datos).codificar ('ASCII') Finalmente, podemos enviar nuestra solicitud, pasando los datos como el segundo argumento del urgente función. En este caso usaremos https: // httpbin.org/post como url de destino (httpbin.org es un servicio de solicitud y respuesta):
>>> con Urlopen ("https: // httpbin.org/post ", post_data) como respuesta: ... JSON_RESPONSE = JSON.load (respuesta) >>> pPrint (json_response) 'args': , 'data': ", 'archivos': , 'form': 'variable1': 'valor1', 'variable2': ' value2 ',' encabezados ': ' aceptar-ending ':' identidad ',' contenido-longitud ':' 33 ',' contenido-type ':' aplicación/x-www-form-urlencoded ',' host ' : 'httpbin.org ',' agente de usuario ':' Python-urllib/3.7 ',' json ': ninguno,' origen ':' xx.xx.xx.xx, xx.xx.xx.xx ',' url ':' https: // httpbin.org/post ' La solicitud fue exitosa y el servidor devolvió una respuesta JSON que incluye información sobre la solicitud que hicimos. Como puede ver, las variables que pasamos en el cuerpo de la solicitud se informan como el valor del 'forma' clave en el cuerpo de respuesta. Leyendo el valor del encabezado clave, también podemos ver que el tipo de contenido de la solicitud fue aplicación/x-www-form-urlencoded y el agente de usuario 'Python-urllib/3.7 '.
Enviar datos JSON en la solicitud
¿Qué pasa si queremos enviar una representación de datos JSON con nuestra solicitud?? Primero definimos la estructura de los datos que lo convirtimos a JSON:
>>> persona = ... "FirstName": "Luke", ... "LastName": "Skywalker", ... "Título": "Jedi Knight" ... También queremos usar un diccionario para definir encabezados personalizados. En este caso, por ejemplo, queremos especificar que nuestro contenido de solicitud sea Aplicación/JSON:
>>> Custom_headers = ... "Tipo de contenido": "Aplicación/JSON" ... Finalmente, en lugar de enviar la solicitud directamente, creamos un Pedido objeto y pasamos, en orden: la URL de destino, los datos de solicitud y los encabezados de solicitud como argumentos de su constructor:
>>> de Urllib.Solicitar la solicitud de importación >>> req = solicitud ( ... "https: // httpbin.org/post ", ... json.vertederos (persona).codificar ('ASCII'), ... Custom_headers ...) Una cosa importante a notar es que usamos el json.deshecho función que pasa el diccionario que contiene los datos que queremos que se incluyan en la solicitud como su argumento: esta función se utiliza para fabricar en serie un objeto en una cadena formateada JSON, que codificamos usando el codificar método.
En este punto podemos enviar nuestro Pedido, pasarlo como el primer argumento del urgente función:
>>> con Urlopen (REQ) como respuesta: ... JSON_RESPONSE = JSON.Carga (respuesta) Verifiquemos el contenido de la respuesta:
'Args': , 'Data': '"FirstName": "Luke", "LastName": "SkyWalker", "Title": "Jedi" Knight "', 'Archivos': , ' Forma ': ,' encabezados ': ' aceptación de aceptación ':' identidad ',' contenido-longitud ':' 70 ',' content-type ':' aplicación/json ',' host ':' httpbin.org ',' agente de usuario ':' Python-urllib/3.7 ',' Json ': ' FirstName ':' Luke ',' LastName ':' Skywalker ',' Title ':' Jedi Knight ',' Origin ':' xx.xx.xx.xx, xx.xx.xx.xx ',' url ':' https: // httpbin.org/post ' Esta vez podemos ver que el diccionario asociado con la clave de "forma" en el cuerpo de respuesta está vacía, y la asociada con la tecla "JSON" representa los datos que enviamos como JSON. Como puede observar, incluso el parámetro de encabezado personalizado que enviamos se ha recibido correctamente.
Enviar una solicitud con un verbo http que no sea obtener o publicar
Al interactuar con API, es posible que necesitemos usar Verbos http Aparte de solo obtener o publicar. Para lograr esta tarea debemos usar el último parámetro del Pedido Constructor de clase y especifique el verbo que queremos usar. El verbo predeterminado es obtener si el datos El parámetro es Ninguno, de lo contrario se usa la publicación. Supongamos que queremos enviar un PONER pedido:
>>> req = solicitud ( ... "https: // httpbin.org/put ", ... json.vertederos (persona).codificar ('ASCII'), ... Custom_headers, ... método = 'Put' ...) Descargar un archivo
Otra operación muy común que deseamos realizar es descargar algún tipo de archivo de la web. Usando la biblioteca estándar, hay dos formas de hacerlo: usar el urgente función, leer la respuesta en fragmentos (especialmente si el archivo para descargar es grande) y escribirlos en un archivo local "manualmente" o usar el urlcrecie La función, que, como se indica en la documentación oficial, se considera parte de una interfaz antigua, y podría desaprobarse en el futuro. Veamos un ejemplo de ambas estrategias.
Descargar un archivo usando Urlopen
Digamos que queremos descargar el tarball que contiene la última versión del código fuente del núcleo de Linux. Usando el primer método que mencionamos anteriormente, escribimos:
>>> ortat_kernel_tarball = "https: // cdn.núcleo.org/pub/linux/kernel/v5.X/Linux-5.0.7.alquitrán.xz ">>> con Urlopen (ortat_kernel_tarball) como respuesta: ... con Open ('último kernel.alquitrán.xz ',' wb ') como tarball: ... Mientras que es cierto: ... trozo = respuesta.Leer (16384) ... Si fragmenta: ... tarball.Escribir (trozo) ... demás: ... romper En el ejemplo anterior, primero usamos ambos urgente función y el abierto Uno con declaraciones y, por lo tanto, utilizando el protocolo de gestión de contexto para garantizar que los recursos se limpien inmediatamente después de que se ejecute el bloque de código donde se usan. Dentro de una mientras bucle, en cada iteración, el pedazo Referencias variables Los bytes se leen de la respuesta, (16384 en este caso - 16 kibibytes). Si pedazo no está vacío, escribimos el contenido al objeto de archivo ("Tarball"); Si está vacío, significa que consumimos todo el contenido del cuerpo de respuesta, por lo tanto, rompimos el bucle.
Una solución más concisa implica el uso de la callar biblioteca y el copyFileObj función, que copia datos de un objeto similar al archivo (en este caso "respuesta") a otro objeto similar a un archivo (en este caso, "tarball"). El tamaño del búfer se puede especificar utilizando el tercer argumento de la función, que, por defecto, se establece en 16384 bytes):
>>> SALIENTO DE IMPORTACIÓN ... con Urlopen (último_kernel_tarball) como respuesta: ... con Open ('último kernel.alquitrán.xz ',' wb ') como tarball: ... callar.copyFileObj (respuesta, tarball) Descargar un archivo utilizando la función Urlretrieve
El método alternativo y aún más conciso para descargar un archivo utilizando la biblioteca estándar es mediante el uso del urllib.pedido.urlcrecie función. La función toma cuatro argumentos, pero solo los dos primeros nos interesan ahora: el primero es obligatorio y es la URL del recurso para descargar; El segundo es el nombre utilizado para almacenar el recurso localmente. Si no se da, el recurso se almacenará como un archivo temporal en /TMP. El código se convierte en:
>>> de Urllib.Solicitar la importación de urlretieve >>> Urlretrieve ("https: // cdn.núcleo.org/pub/linux/kernel/v5.X/Linux-5.0.7.alquitrán.xz ") ('último kernel.alquitrán.xz ', ) Muy simple, ¿no?? La función devuelve una tupla que contiene el nombre utilizado para almacenar el archivo (esto es útil cuando el recurso se almacena como archivo temporal, y el nombre es generado aleatorio), y el Httpmessage objeto que contiene los encabezados de la respuesta HTTP.
Conclusiones
En esta primera parte de la serie de artículos dedicados a las solicitudes de Python y HTTP, vimos cómo enviar varios tipos de solicitudes utilizando solo funciones de biblioteca estándar y cómo trabajar con respuestas. Si tiene dudas o desea explorar las cosas más en profundidad, consulte al Oficial Oficial Urllib.solicitar documentación. La siguiente parte de la serie se centrará en la biblioteca de solicitudes de Python HTTP.
Tutoriales de Linux relacionados:
- Una introducción a la automatización, herramientas y técnicas de Linux
- Mastering Bash Script Loops
- Bucles anidados en guiones Bash
- Mint 20: Mejor que Ubuntu y Microsoft Windows?
- Cosas para instalar en Ubuntu 20.04
- Cómo trabajar con la API REST de WooCommerce con Python
- Cómo iniciar procesos externos con Python y el ..
- Manejo de la entrada del usuario en scripts bash
- Cómo cargar, descargar y módulos de núcleos Linux de la lista negra
- Sistema colgado de Linux? Cómo escapar a la línea de comando y ..
- « Introducción a la base de datos se une a los ejemplos de mariadb y mysql unirse
- Cómo realizar solicitudes HTTP con Python - Parte 2 - La biblioteca de solicitudes »