

Cómo recuperar datos y reconstruir las redadas de software fallidas - Parte 8

- 3822
- 351
- Adriana Tórrez
En los artículos anteriores de esta serie RAID, pasaste de cero a héroe atrasado. Revisamos varias configuraciones de RAID de software y explicamos los elementos esenciales de cada uno, junto con las razones por las que se inclinaría hacia uno u otro dependiendo de su escenario específico.
 Recuperar la reconstrucción del software fallido RAID - Parte 8
Recuperar la reconstrucción del software fallido RAID - Parte 8 En esta guía discutiremos cómo reconstruir una matriz de redadas de software sin pérdida de datos cuando en el caso de una falla en el disco. Para la brevedad, solo consideraremos un Incursión 1 configuración: pero los conceptos y comandos se aplican a todos los casos por igual.
Escenario de prueba de RAID
Antes de continuar, asegúrese de haber configurado un Incursión 1 matriz siguiendo las instrucciones proporcionadas en la Parte 3 de esta serie: Cómo configurar RAID 1 (Mirror) en Linux.
Las únicas variaciones en nuestro presente caso serán:
1) Una versión diferente de CentOS (V7) que la utilizada en ese artículo (V6.5) y
2) diferentes tamaños de disco para /dev/sdb y /dev/sdc (8 GB cada uno).
Además, si Selinux está habilitado en modo de aplicación, deberá agregar las etiquetas correspondientes al directorio donde montará el dispositivo RAID. De lo contrario, se encontrará con este mensaje de advertencia al intentar montarlo:
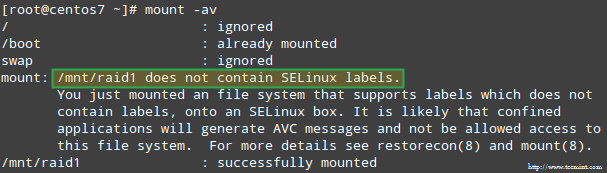 Error de montaje de Raid Selinux
Error de montaje de Raid Selinux Puedes arreglar esto ejecutando:
# Restorecon -r /Mnt /Raid1
Configuración de monitoreo de RAID
Sin embargo, hay una variedad de razones por las cuales un dispositivo de almacenamiento puede fallar (sin embargo, los SSD han reducido en gran medida las posibilidades de que esto suceda), pero independientemente de la causa, puede estar seguro de que los problemas pueden ocurrir en cualquier momento y debe estar preparado para reemplazar el fallido Parte y para garantizar la disponibilidad e integridad de sus datos.
Un consejo primero. Incluso cuando puedas inspeccionar /proc/mdstat Para verificar el estado de sus redadas, hay un método mejor y de ahorro de tiempo que consiste en ejecutar mada en el modo Monitor + Scan, que enviará alertas por correo electrónico a un destinatario predefinido.
Para configurar esto, agregue la siguiente línea en /etc/mdadm.confusión:
Mailaddr [correo electrónico protegido]
En mi caso:
Mailaddr [correo electrónico protegido]
 RAID Monitorear alertas por correo electrónico
RAID Monitorear alertas por correo electrónico Correr mada En el modo Monitor + Scan, agregue la siguiente entrada de CRONTAB como raíz:
@reboot /sbin /mdadm --monitor --scan --onhot
Por defecto, mada Verificará las matrices de redadas cada 60 segundos y enviará una alerta si encuentra un problema. Puede modificar este comportamiento agregando el --demora Opción para la entrada CRONTAB anterior junto con la cantidad de segundos (por ejemplo, --demora 1800 significa 30 minutos).
Finalmente, asegúrese de tener un Correo de agente de usuario (MUA) instalado, como Mutt o Mailx. De lo contrario, no recibirá ninguna alerta.
En un minuto veremos lo que envió una alerta por mada parece.
Simular y reemplazar un dispositivo de almacenamiento RAID fallido
Para simular un problema con uno de los dispositivos de almacenamiento en la matriz RAID, utilizaremos el --administrar y --femenino Opciones de la siguiente manera:
# MDADM --Manage --set-Faulty /dev /md0 /dev /sdc1
Esto dará como resultado en /dev/sdc1 estar marcado como defectuoso, como podemos ver en /proc/mdstat:
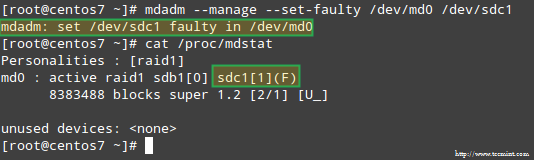 Estimular el problema con el almacenamiento de RAID
Estimular el problema con el almacenamiento de RAID Más importante aún, veamos si recibimos una alerta por correo electrónico con la misma advertencia:
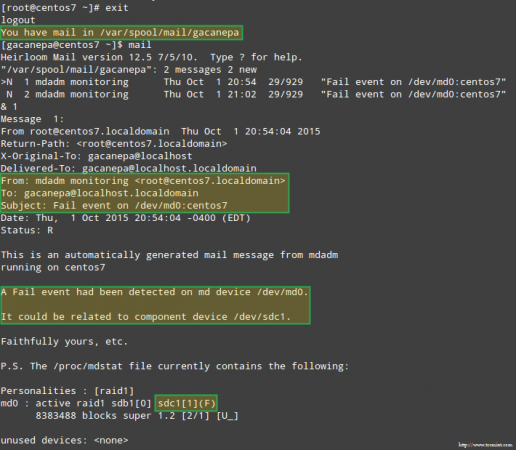 Alerta de correo electrónico en el dispositivo RAID fallido
Alerta de correo electrónico en el dispositivo RAID fallido En este caso, deberá eliminar el dispositivo de la matriz RAID de software:
# mdadm /dev /md0 ---remove /dev /sdc1
Luego puede eliminarlo físicamente de la máquina y reemplazarla con una parte de repuesto (/dev/sdd, donde una partición de tipo fd ha sido creado previamente):
# MDADM --Manage /dev /md0 --add /dev /sdd1
Afortunadamente para nosotros, el sistema comenzará a reconstruir automáticamente la matriz con la parte que acabamos de agregar. Podemos probar esto marcando /dev/sdb1 tan defectuoso, eliminarlo de la matriz y asegurarse de que el archivo tecmenta.TXT todavía es accesible en /Mnt/Raid1:
# mDadm --detail /dev /md0 # monte | GREP RAID1 # LS -L /MNT /RAID1 | Grep Tecmint # Cat/Mnt/Raid1/Tecmint.TXT
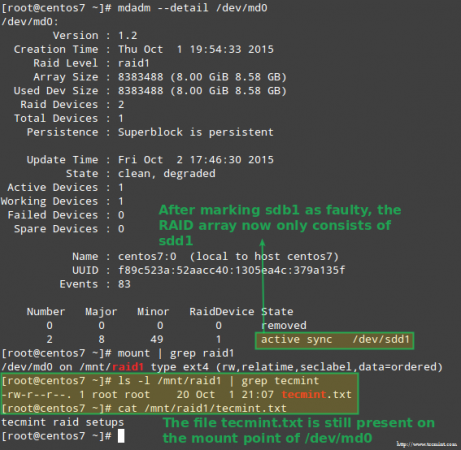 Confirmar una matriz de redacción de reconstrucción
Confirmar una matriz de redacción de reconstrucción La imagen de arriba muestra claramente que después de agregar /dev/sdd1 a la matriz como reemplazo para /dev/sdc1, El sistema realizó automáticamente la reconstrucción de datos sin intervención de nuestra parte.
Aunque no se requiere estrictamente, es una gran idea tener un dispositivo de repuesto a mano para que el proceso de reemplazar el dispositivo defectuoso con una buena unidad se pueda hacer en un instante. Para hacer eso, volvamos a agregar /dev/sdb1 y /dev/sdc1:
# MDADM --Manage /dev /md0 --add /dev /sdb1 # mdadm --manage /dev /md0 --add /dev /sdc1
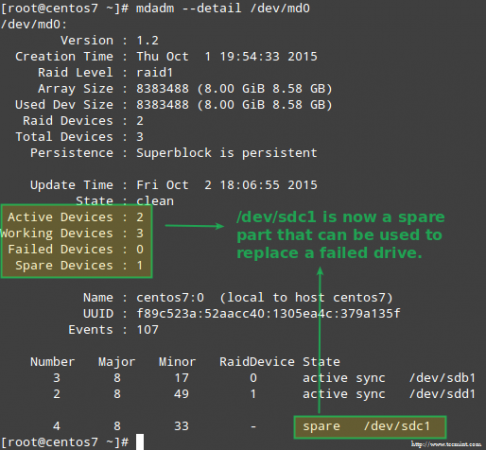 Reemplace el dispositivo RAID fallido
Reemplace el dispositivo RAID fallido Recuperarse de una pérdida de redundancia
Como se explicó anteriormente, mada reconstruirá automáticamente los datos cuando falle un disco. Pero, ¿qué sucede si fallan 2 discos en la matriz?? Simulemos tal escenario marcando /dev/sdb1 y /dev/sdd1 Como defectuoso:
# Umount /Mnt /Raid1 # MDADM --Manage --set-Faulty /dev /md0 /dev /sdb1 # mdadm--stop /dev /md0 # mdadm --grayage --set-faulty /dev /md0 /dev / sdd1
Intenta recrear la matriz de la misma manera que se creó en este momento (o usando el --asumir limpio opción) puede dar lugar a la pérdida de datos, por lo que debe dejarse como un último recurso.
Intentemos recuperar los datos de /dev/sdb1, Por ejemplo, en una partición de disco similar (/dev/sde1 - Tenga en cuenta que esto requiere que cree una partición de tipo fd en /dev/sde antes de continuar) usando ddRescue:
# ddrescue -r 2 /dev /sdb1 /dev /sde1
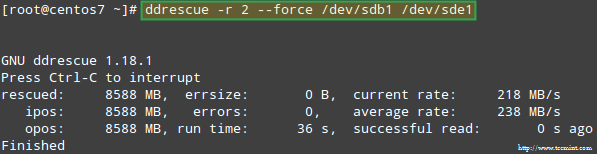 Array de recuperación de RAID
Array de recuperación de RAID Tenga en cuenta que hasta este punto, no hemos tocado /dev/sdb o /dev/sdd, las particiones que formaron parte de la matriz de incursión.
Ahora reconstruamos la matriz usando /dev/sde1 y /dev/sdf1:
# MDADM-CREATE /DEV /MD0 --LEVEL = MIRROR--RAID-DEVICES = 2 /dev /SD [E-F] 1
Tenga en cuenta que en una situación real, generalmente usará los mismos nombres de dispositivos que con la matriz original, es decir, /dev/sdb1 y /dev/sdc1 Después de que los discos fallidos hayan sido reemplazados por nuevos.
En este artículo, he optado por usar dispositivos adicionales para recrear la matriz con discos nuevos y evitar confusiones con las unidades fallidas originales.
Cuando se le preguntó si continuará escribiendo una matriz, escriba Y y presionar Ingresar. La matriz debe iniciarse y debería poder ver su progreso con:
# reloj -n 1 Cat /Proc /Mdstat
Cuando se completa el proceso, debería poder acceder al contenido de su incursión:
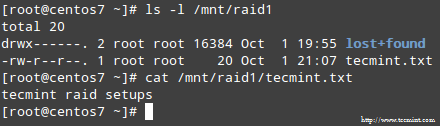 Confirmar contenido de RAID
Confirmar contenido de RAID Resumen
En este artículo hemos revisado cómo recuperarnos de REDADA fallas y pérdidas de redundancia. Sin embargo, debe recordar que esta tecnología es una solución de almacenamiento y NO ES Reemplazar copias de seguridad.
Los principios explicados en esta guía se aplican tanto a todas las configuraciones de RAID, así como a los conceptos que cubriremos en la próxima y última guía de esta serie (RAID Management).
Si tiene alguna pregunta sobre este artículo, no dude en dejarnos una nota utilizando el formulario de comentarios a continuación. Esperamos con interés escuchar de usted!
- « Cómo obtener información de hardware con el comando dmidecode en Linux
- Powerline agrega potentes líneas de estado y indicaciones a Vim Editor y Bash Terminal »