

Cómo configurar Hadoop en Ubuntu 18.04 y 16.04 LTS

- 4509
- 39
- Sr. Eduardo Menchaca
Apache Hadoop 3.1 tener mejoras notables cualquier muchas correcciones de errores en el establo anterior 3.0 lanzamientos. Esta versión tiene muchas mejoras en HDFS y MapReduce. Este tutorial lo ayudará a instalar y configurar Hadoop 3.1.2 Clúster de un solo nodo en ubuntu 18.04, 16.04 sistemas LTS y LinuxMint. Este artículo ha sido probado con Ubuntu 18.04 LTS.
Paso 1 - Prerequusidades
Java es el requisito principal para ejecutar Hadoop en cualquier sistema, así que asegúrese de tener Java instalado en su sistema utilizando el siguiente comando. Si no tiene Java instalado en su sistema, use uno de los siguientes enlaces para instalarlo primero.
- Instale Oracle Java 11 en Ubuntu 18.04 LTS (Bionic)
- Instale Oracle Java 11 en Ubuntu 16.04 LTS (xenial)
Paso 2: crear usuario para haddop
Recomendamos crear una cuenta normal (ni raíz) para que funcione Hadoop. Para crear una cuenta utilizando el siguiente comando.
adduser hadoop
Después de crear la cuenta, también requirió configurar SSH basado en clave en su propia cuenta. Para hacer esto, use los comandos de ejecución de los siguientes.
Su -Hadoop SSH -Keygen -T RSA -P "-F ~/.SSH/ID_RSA CAT ~/.ssh/id_rsa.Pub >> ~/.ssh/autorized_keys chmod 0600 ~/.ssh/autorized_keys
Ahora, ssh a localhost con el usuario de Hadoop. Esto no debe solicitar la contraseña, pero la primera vez solicitará agregar RSA a la lista de hosts conocidos.
SSH Localhost Salida
Paso 3 - Descargar Hadoop Source Archive
En este paso, descarga Hadoop 3.1 archivo de archivo de origen usando el siguiente comando. También puede seleccionar el espejo de descarga alternativo para aumentar la velocidad de descarga.
CD ~ wget http: // www-eu.apache.org/Dist/Hadoop/Common/Hadoop-3.1.2/Hadoop-3.1.2.alquitrán.gz tar xzf hadoop-3.1.2.alquitrán.GZ MV Hadoop-3.1.2 Hadoop
Paso 4 - Configurar el modo pseudop -distribuido de Hadoop
4.1. Configurar variables de entorno Hadoop
Configurar las variables de entorno utilizadas por el Hadoop. Editar ~/.bashrc archivo y agregar los siguientes valores al final del archivo.
Exportar hadoop_home =/home/hadoop/hadoop Export hadoop_install = $ hadoop_home exportoop_mapred_home = $ hadoop_home export hadoop_common_home = $ hadoop_home exportoop_hdfs_home = $ hadoop_home exports_home = $ hadoop_home export_home hadoop_common_nib_nib_natative Hadoop_home/sbin: $ hadoop_home/bin
Luego, aplique los cambios en el entorno de ejecución actual
fuente ~/.bashrc
Ahora editar $ Hadoop_home/etc/hadoop/hadoop-env.mierda archivo y establecer Java_home Variable ambiental. Cambie la ruta Java según la instalación en su sistema. Esta ruta puede variar según la versión de su sistema operativo y la fuente de instalación. Así que asegúrese de estar usando la ruta correcta.
vim $ hadoop_home/etc/hadoop/hadoop-envv.mierda
Actualización a continuación Entrada:
Exportar java_home =/usr/lib/jvm/java-11-oracle
4.2. Configurar archivos de configuración de Hadoop
Hadoop tiene muchos archivos de configuración, que deben configurar según los requisitos de su infraestructura de Hadoop. Comencemos con la configuración con la configuración básica del clúster de nodo único Hadoop. Primero, navegue a la ubicación a continuación
CD $ hadoop_home/etc/hadoop
Editar el sitio de núcleo.xml
FS.por defecto.nombre hdfs: // localhost: 9000
Editar el sitio HDFS.xml
DFS.Replicación 1 DFS.nombre.Archivo Dir: /// home/hadoop/hadoopdata/hdfs/nameNode DFS.datos.archivo dir: /// home/hadoop/hadoopdata/hdfs/datanode
Editar el sitio de mapred.xml
Mapa reducido.estructura.hilo de nombre
Editar el hilo.xml
hilo.nodo.Aux-Services MapReduce_Shuffle
4.3. Formatear namenode
Ahora formatea el NameNode usando el siguiente comando, asegúrese de que el directorio de almacenamiento sea
HDFS namenode -Format
Salida de muestra:
Advertencia:/home/hadoop/hadoop/logs no existe. Creación. 2018-05-02 17: 52: 09,678 Información Namenode.Namenode: startup_msg: /********************************************** ***************** Startup_msg: iniciar Namenode startup_msg: host = tecadmin/127.0.1.1 startup_msg: args = [-format] startup_msg: versión = 3.1.2 ... 2018-05-02 17: 52: 13,717 Información común.Almacenamiento: el directorio de almacenamiento/home/hadoop/hadoopdata/hdfs/namenode se ha formateado correctamente. 2018-05-02 17: 52: 13,806 Información Namenode.FSIMAGEFORMATPROTOBUF: Guardar el archivo de imagen/home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.CKPT_000000000000000000000 UTILIZANDO COMPRESIÓN 2018-05-02 17: 52: 14,161 Información Namenode.FSIMAGEFORMATPROTOBUF: FILE DE IMAGEN/HOME/HADOOP/HADOOPDATA/HDFS/NAMENODE/Current/FSIMAGE.CKPT_000000000000000000000 de tamaño 391 bytes guardados en 0 segundos . 2018-05-02 17: 52: 14,224 Información Namenode.NnstorageretentionManager: va a retener 1 imágenes con txid> = 0 2018-05-02 17: 52: 14,282 Información Namenode.Namenode: shutdown_msg: /******************************************** ***************** Callado_msg: Apagando Namenode en Tecadmin/127.0.1.1 ****************************************************** ***********/
Paso 5 - Inicie Hadoop Cluster
Comencemos su clúster de Hadoop usando los scripts proporcionados por Hadoop. Simplemente navegue a su directorio $ hadoop_home/sbin y ejecute scripts uno por uno.
CD $ hadoop_home/sbin/
Ahora ejecutar inicio-DFS.mierda guion.
./Start-DFS.mierda
Luego ejecutar start-yarn.mierda guion.
./Start-yarn.mierda
Paso 6 - Acceder a los servicios de Hadoop en el navegador
Hadoop Namenode comenzó en el puerto predeterminado 9870. Acceda a su servidor en el puerto 9870 en su navegador web favorito.
http: // svr1.tecadmin.NET: 9870/
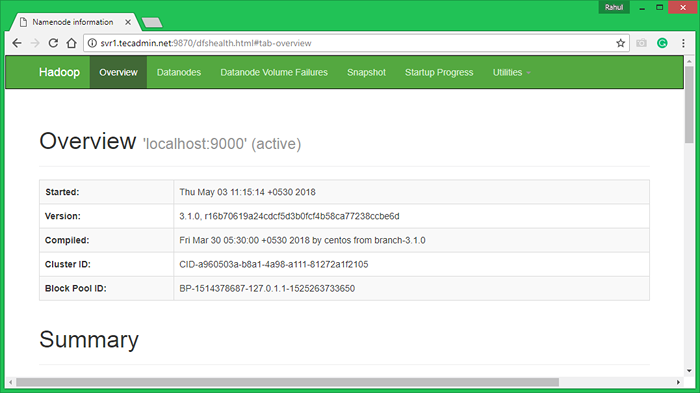
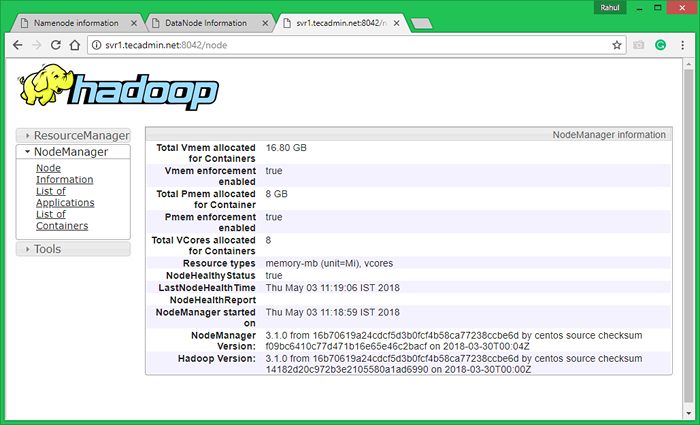
Ahora acceda al puerto 8042 para obtener la información sobre el clúster y todas las aplicaciones
http: // svr1.tecadmin.NET: 8042/
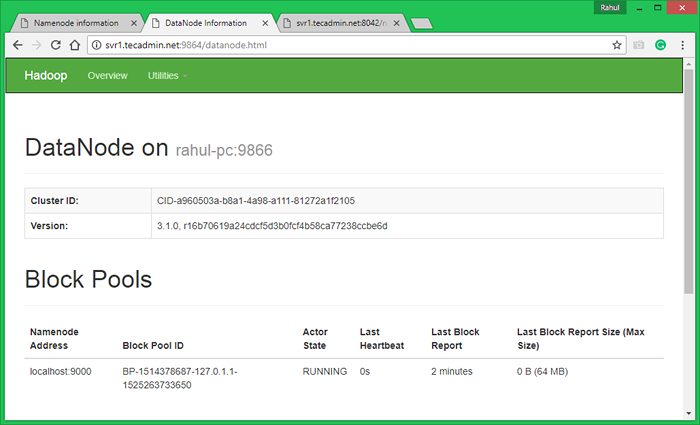
Puerto de acceso 9864 para obtener detalles sobre su nodo Hadoop.
http: // svr1.tecadmin.NET: 9864/
Paso 7: prueba la configuración de nodo único de Hadoop
7.1. Haga que los directorios HDFS se requieran utilizando los siguientes comandos.
bin/hdfs dfs -mkdir/usuario bin/hdfs dfs -mkdir/user/hadoop
7.2. Copie todos los archivos del sistema local de archivos/var/log/httpd al sistema de archivos distribuido Hadoop usando el siguiente comando
bin/hdfs dfs -put/var/log/apache2 registra
7.3. Explore el sistema de archivos distribuido Hadoop abriendo a continuación URL en el navegador. Verá una carpeta Apache2 en la lista. Haga clic en el nombre de la carpeta para abrir y encontrará todos los archivos de registro allí.
http: // svr1.tecadmin.NET: 9870/Explorer.html#/user/hadoop/logs/
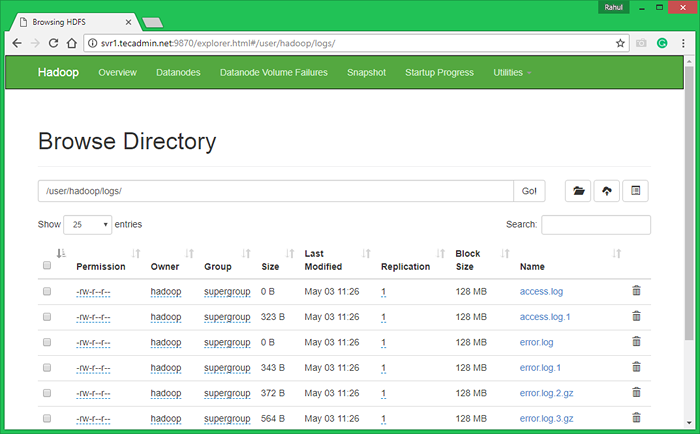
7.4 - Ahora copie el directorio de registros para el sistema de archivos distribuido Hadoop al sistema de archivos local.
bin/hdfs dfs -get logs/tmp/logs ls -l/tmp/logs/
También puede verificar este tutorial para ejecutar WordCount MapReduce Ejemplo de trabajo usando la línea de comandos.
- « Cómo detectar el entorno de escritorio en la línea de comandos de Linux
- Cómo descargar y cargar archivos con el comando SFTP »