

Instale el clúster multinodo de Hadoop usando CDH4 en Rhel/Centos 6.5

- 2424
- 397
- Mateo Pantoja
Hadoop es un marco de programación de código abierto desarrollado por Apache para procesar grandes datos. Usa HDFS (Sistema de archivos distribuido Hadoop) para almacenar los datos en todos los datanodes en el clúster de manera distributiva y modelo MapReduce para procesar los datos.
 Instale el clúster multinodo de Hadoop
Instale el clúster multinodo de Hadoop Namenode (Nn) es un demonio maestro que controla HDFS y Jobtracker (Jt) es maestro demonio para el motor MapReduce.
Requisitos
En este tutorial estoy usando dos Centos 6.3 Vms 'maestro' y 'nodo'a saber. (Master y Node son mis nombres de host). El IP 'maestro' es 172.21.17.175 y el nodo IP es '172.21.17.188'. Las siguientes instrucciones también funcionan en Rhel/Centos 6.X versiones.
En el maestro
[[Correo electrónico protegido] ~]# HostName maestro
[[correo electrónico protegido] ~]# ifconfig | grep 'inet addr' | head -1 inet addr:172.21.17.175 Bcast: 172.21.19.255 máscara: 255.255.252.0
En el nodo
[[Correo electrónico protegido] ~]# HostName nodo
[[correo electrónico protegido] ~]# ifconfig | grep 'inet addr' | head -1 inet addr:172.21.17.188 Bcast: 172.21.19.255 máscara: 255.255.252.0
Primero asegúrese de que todos los hosts de clúster estén allí en '/etc/huéspedes'Archivo (en cada nodo), si no tiene DNS configurado.
En el maestro
[[correo electrónico protegido] ~]# cat /etc /hosts 172.21.17.175 maestro 172.21.17.188 nodo
En el nodo
[[correo electrónico protegido] ~]# cat /etc /hosts 172.21.17.197 Qabox 172.21.17.176 Ansible-Ground
Instalación del clúster multinodo de Hadoop en CentOS
Usamos oficiales CDH repositorio para instalar CDH4 en todos los hosts (maestro y nodo) en un clúster.
Paso 1: Descargar Instalar repositorio CDH
Vaya a la página oficial de descarga de CDH y tome el CDH4 (i.mi. 4.6) Versión o puedes usar siguiendo wget comandar para descargar el repositorio e instalarlo.
En RHEL/CENTOS 32 bits
# wget http: // Archive.cloudera.com/CDH4/One-Click-Install/Redhat/6/I386/Cloudera-CDH-4-0.i386.RPM # yum--nogpgcheck localinstall Cloudera-cdh-4-0.i386.rpm
En RHEL/CENTOS 64 bits
# wget http: // Archive.cloudera.com/cdh4/one-click-install/redhat/6/x86_64/cloudera-cdh-4-0.x86_64.RPM # yum--nogpgcheck localinstall Cloudera-cdh-4-0.x86_64.rpm
Antes de instalar el clúster multinodo de Hadoop, agregue la tecla Cloudera Public GPG a su repositorio ejecutando uno de los siguientes comando de acuerdo con la arquitectura de su sistema.
## en el sistema de 32 bits ## # rpm --import http: // Archive.cloudera.com/cdh4/redhat/6/i386/cdh/rpm-gpg-key-clouDera
## en el sistema de 64 bits ## # rpm --import http: // Archive.cloudera.com/cdh4/redhat/6/x86_64/cdh/rpm-gpg-key-ncoudera
Paso 2: Configurar JobTracker y Namenode
A continuación, ejecute el siguiente comando para instalar y configurar JobTracker y Namenode en Master Server.
[[correo electrónico protegido] ~]# yum limpia todo [[correo electrónico protegido] ~]# yum install hadoop-0.20-Mapreduce-Jobtracker
[[Correo electrónico protegido] ~]# yum limpia todo [[correo electrónico protegido] ~]# yum install hadoop-hdfs-namenode
Paso 3: Configuración del nodo de nombre secundario
Nuevamente, ejecute los siguientes comandos en el servidor maestro para configurar el nodo de nombre secundario.
[[Correo electrónico protegido] ~]# yum limpia todo [[correo electrónico protegido] ~]# yum instalar hadoop-hdfs-secondarynam
Paso 4: Configuración de TaskTracker y Datanode
A continuación, configure TaskTracker & Datanode en todos los hosts de clúster (nodo), excepto los hosts JobTracker, NameNode y Secondary (o Standby) NameNode (en el nodo en este caso).
[[correo electrónico protegido] ~]# yum limpia todo [[correo electrónico protegido] ~]# yum install hadoop-0.20-mapreduce-tasktracker hadoop-hdfs-datanode
Paso 5: Configurar el cliente Hadoop
Puede instalar el cliente Hadoop en una máquina separada (en este caso, la he instalado en Datanode, puede instalarlo en cualquier máquina).
[[correo electrónico protegido] ~]# yum instalar hadoop-client
Paso 6: Implementar HDFS en nodos
Ahora, si hemos terminado con los pasos anteriores, avancemos para implementar HDFS (para hacer en todos los nodos).
Copie la configuración predeterminada a /etc/hadoop Directorio (en cada nodo en el clúster).
[[correo electrónico protegido] ~]# cp -r/etc/hadoop/conf.dist/etc/hadoop/conf.my_cluster
[[correo electrónico protegido] ~]# cp -r/etc/hadoop/conf.dist/etc/hadoop/conf.my_cluster
Usar alternativas Comando para establecer su directorio personalizado, como sigue (en cada nodo en el clúster).
[[correo electrónico protegido] ~]# alternativas --verbose --install/etc/hadoop/conf hadoop-conf/etc/hadoop/conf.my_cluster 50 lectura/var/lib/alternativas/hadoop-confio [[correo electrónico protegido] ~]# alternativas --set hadoop-conf/etc/hadoop/conf.my_cluster
[[correo electrónico protegido] ~]# alternativas --verbose --install/etc/hadoop/conf hadoop-conf/etc/hadoop/conf.my_cluster 50 lectura/var/lib/alternativas/hadoop-confio [[correo electrónico protegido] ~]# alternativas --set hadoop-conf/etc/hadoop/conf.my_cluster
Paso 7: Personalización de archivos de configuración
Ahora abierto 'sitio de núcleo.xml'Archivo y actualización "FS.defaultfs"En cada nodo en el clúster.
[[correo electrónico protegido] conf]# cat/etc/hadoop/conf/core-site.xml
FS.defaultfs hdfs: // maestro/
[[correo electrónico protegido] conf]# cat/etc/hadoop/conf/core-site.xml
FS.defaultfs hdfs: // maestro/
Siguiente actualización "DFS.permisos.grupo de superuser" en sitio HDFS.xml en cada nodo en el clúster.
[[correo electrónico protegido] conf]# cat/etc/hadoop/conf/hdfs-site.xml
DFS.nombre.prostituta /var/lib/hadoop-hdfs/caché/hdfs/dfs/name DFS.permisos.SuperuserGroup Hadoop
[[correo electrónico protegido] conf]# cat/etc/hadoop/conf/hdfs-site.xml
DFS.nombre.prostituta /var/lib/hadoop-hdfs/caché/hdfs/dfs/name DFS.permisos.SuperuserGroup Hadoop
Nota: Asegúrese de que la configuración anterior esté presente en todos los nodos (haga en un nodo y ejecute SCP para copiar en el resto de los nodos).
Paso 8: Configuración de directorios de almacenamiento local
Actualizar "DFS.nombre.Dir o DFS.namenode.nombre.dir ”en 'hdfs-site.XML 'en el Namenode (en Master y Node). Cambie el valor como se resalta.
[[correo electrónico protegido] conf]# cat/etc/hadoop/conf/hdfs-site.xml
DFS.namenode.nombre.prostituta archivo: /// data/1/dfs/nn,/nfmount/dfs/nn
[[correo electrónico protegido] conf]# cat/etc/hadoop/conf/hdfs-site.xml
DFS.datanode.datos.prostituta archivo: /// data/1/dfs/dn,/data/2/dfs/dn,/data/3/dfs/dn
Paso 9: Crear directorios y administrar permisos
Ejecutar los comandos a continuación para crear estructura de directorio y administrar los permisos de usuario en la máquina NameNode (Master) y DataNode (Node).
[[Correo electrónico protegido]]# mkdir -p/data/1/dfs/nn/nfmount/dfs/nn [[correos electrónicos protegidos]]# chmod 700/data/1/dfs/nn/nfsmount/dfs/nn
[[Correo electrónico protegido]]# mkdir -p/data/1/dfs/dn/data/2/dfs/dn/data/3/dfs/dn/data/4/dfs/dn [[correo electrónico protegido]]# Chown -R hdfs: hdfs/data/1/dfs/nn/nfmount/dfs/nn/data/1/dfs/dn/data/2/dfs/dn/data/3/dfs/dn/data/4/dfs/ dn
Formatear el NameNode (en el maestro), emitiendo el siguiente comando.
[[correo electrónico protegido] conf]# sudo -u hdfs hdfs namenode -format
Paso 10: Configuración del NameNode secundario
Agregue la siguiente propiedad al sitio HDFS.xml archivo y reemplazar el valor como se muestra en el maestro.
DFS.namenode.http-dirdress 172.21.17.175: 50070 La dirección y el puerto en el que escuchará la interfaz de usuario de Namenode.
Nota: En nuestro caso el valor debe ser la dirección IP de Master VM.
Ahora implementemos MRV1 (Map-Reduce Versión 1). Abierto 'sitio de mapred.xml'Archivo los siguientes valores como se muestra.
[[correo electrónico protegido] conf]# cp hdfs-site.XML Mapred Site.XML [[Correo electrónico protegido] conf]# VI Mapred-site.XML [[Correo electrónico protegido] Conf]# Cat Mapred-Site.xml
mapred.trabajo.Tracker Master: 8021
A continuación, copiar 'sitio de mapred.xml'Archivo a la máquina de nodo utilizando el siguiente comando SCP.
[[correo electrónico protegido] conf]# scp/etc/hadoop/conf/mapred-site.nodo XML:/etc/hadoop/conf/mapred-site.XML 100% 200 0.2kb/s 00:00
Ahora configure los directorios de almacenamiento locales para usar por MRV1 Daemons. Nuevamente abierto 'sitio de mapred.xml'Archivo y realice cambios como se muestra a continuación para cada TaskTracker.
 Mapred.local.dir â/data/1/mapred/local,/data/2/mapred/local,/data/3/mapred/local
Después de especificar estos directorios en el 'sitio de mapred.xml'Archivo, debe crear los directorios y asignarles los permisos de archivo correctos en cada nodo en su clúster.
mkdir -p/data/1/mapred/local/data/2/mapred/local/data/3/mapred/local/data/4/mapred/local chown -r Mapred: hadoop/data/1/mapred/local/local/ Datos/2/Mapred/Local/Data/3/Mapred/Local/Data/4/Mapred/Local
Paso 10: Iniciar HDFS
Ahora ejecute el siguiente comando para iniciar HDFS en cada nodo del clúster.
[[correo electrónico protegido] conf]# para x en 'cd /etc /init.d ; ls hadoop-hdfs-*'; hacer servicio sudo $ x inicio; hecho
[[correo electrónico protegido] conf]# para x en 'cd /etc /init.d ; ls hadoop-hdfs-*'; hacer servicio sudo $ x inicio; hecho
Paso 11: Cree directorios HDF /TMP y MapReduce /VAR
Se requiere crear /TMP con los permisos adecuados exactamente como se menciona a continuación.
[[correo electrónico protegido] conf]# sudo -u hdfs hadoop fs -mkdir /tmp [[correo electrónico protegido] conf]# sudo -u hdfs hadoop fs -chmod -r 1777 /tmp
[[Correo electrónico protegido] conf]# sudo -u hdfs hadoop fs -mkdir -p/var/lib/hadoop -hdfs/cache/mapred/mapred/staging [[correo electrónico protegido] conf]# sudo -u hdfs hadoop fs -chmod 1777/var/lib/hadoop -hdfs/cache/mapred/mapred/staging [[correo electrónico protegido] conf]# sudo -u hdfs hadoop fs -ROWN -R Mapred/var/lib/hadoop -hdfs/cache/mapred
Ahora verifique la estructura del archivo HDFS.
[[Correo electrónico protegido] ode conf]# sudo -u hdfs hadoop fs -ls -r / drwxrwxrwt-hdfs hadoop 0 2014-05-29 09:58 / tmp drwxr-xr-x-hdfs hadoop 0 2014-05-29 09 : 59 /var DRWXR-XR-X-HDFS Hadoop 0 2014-05-29 09:59 /var /lib DRWXR-XR-X-HDFS Hadoop 0 2014-05-29 09:59 /var /lib /hadoop-hdfs DRWXR-XR-X-HDFS Hadoop 0 2014-05-29 09:59/var/lib/hadoop-hdfs/cache drwxr-xr-x-Mapred Hadoop 0 2014-05-29 09:59/var/lib/hadoop -hdfs/cache/mapred drwxr-xr-x-mapred hadoop 0 2014-05-29 09:59/var/lib/hadoop-hdfs/cache/mapred/mapred drwxrwxrwt-Mapred Hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/caché/mapred/mapred/staging
Después de comenzar HDFS y crear '/TMP', pero antes de comenzar el JobTracker, cree el directorio HDFS especificado por el' Mapred.sistema.Dir 'Parameter (por defecto $ Hadoop.TMP.dir/mapred/sistema y cambie el propietario a Mapred.
[[Correo electrónico protegido] conf]# sudo -u hdfs hadoop fs -mkdir/tmp/mapred/sistema [[correo electrónico protegido] conf]# sudo -u hdfs hadoop fs -shown mapred: hadoop/tmp/mapred/system
Paso 12: Comience MapReduce
Para comenzar MapReduce: inicie los servicios TT y JT.
En cada sistema de Tasktracker
[[correo electrónico protegido] conf]# servicio hadoop-0.20-Mapreduce-TaskTracker Inicio de inicio de Tasktracker: [OK] Inicio de Tasktracker, registrando/var/log/hadoop-0.20-mapreduce/hadoop-hadoop-tasktracker-nodo.afuera
En el sistema JobTracker
[[correo electrónico protegido] conf]# servicio hadoop-0.20-Mapreduce-JobTracker inicia iniciando Jobtracker: [OK] iniciando Jobtracker, iniciando sesión en/var/log/hadoop-0.20-Mapreduce/Hadoop-Hadoop-Jobtracker-Master.afuera
A continuación, cree un directorio de inicio para cada usuario de Hadoop. Se recomienda que haga esto en Namenode; Por ejemplo.
[[correo electrónico protegido] conf]# sudo -u hdfs hadoop fs -mkdirâ /user /[[correo electrónico protegido] conf]# sudo -u hdfs hadoop fs -shown /user /
Nota: dónde es el nombre de usuario de Linux de cada usuario.
Alternativamente, puede crear el directorio de inicio de la siguiente manera.
[[Correo electrónico protegido] conf]# sudo -u hdfs hadoop fs -mkdir /user /$ user [[correo electrónico protegido] conf]# sudo -u hdfs hadoop fs -wrown $ user /user /$ user
Paso 13: Abrir JT, NN UI del navegador
Abra su navegador y escriba la URL como http: // ip_address_of_namenode: 50070 Para acceder a Namenode.
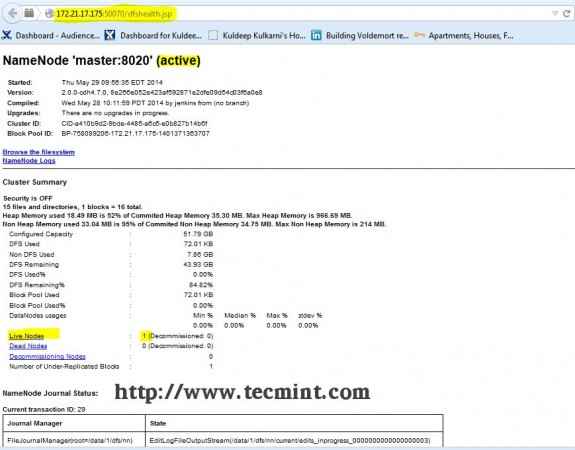 Interfaz Hadoop Namenode
Interfaz Hadoop Namenode Abra otra pestaña en su navegador y escriba la URL como http: // ip_address_of_jobtracker: 50030 Para acceder a Jobtracker.
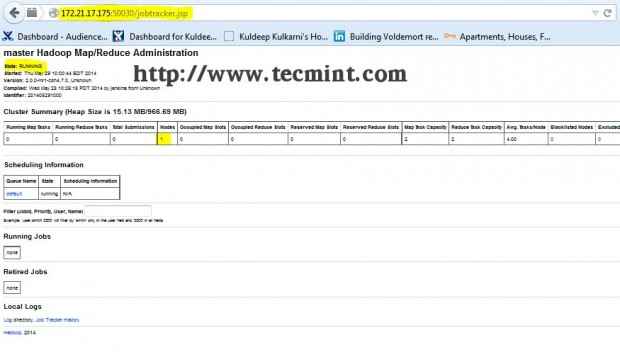 Hadoop map/reducir la administración
Hadoop map/reducir la administración Este procedimiento se ha probado con éxito en RHEL/CENTOS 5.X/6.X. Comente a continuación si enfrenta algún problema con la instalación, lo ayudaré con las soluciones.
- « Cree su propio sitio web para compartir videos utilizando 'Script CumulusClips' en Linux
- Creación de hosts virtuales, generar certificados y teclas SSL y habilitar CGI Gateway en Gentoo Linux »