

Introducción y ventajas/desventajas de la agrupación en Linux - Parte 1

- 3377
- 791
- Sra. Lorena Sedillo
Hola a todos, esta vez decidí compartir mi conocimiento sobre la agrupación de Linux contigo como una serie de guías tituladas "Clustering de Linux para un escenario de conmutación por error".
 ¿Qué se agrupa en Linux y ventajas/desventajas? - Parte 1
¿Qué se agrupa en Linux y ventajas/desventajas? - Parte 1 Las siguientes son la serie de 4 artículos sobre Agrupación En Linux:
Parte 1: Introducción a la agrupación y ventajas/ventajas de Linux Parte 2: Cómo instalar y configurar clúster con dos nodos en Linux Parte 3: Esgrima y agregando una conmutación por error a la agrupación Parte 4: Cómo sincronizar la configuración del clúster y verificar la configuración de conmutación por error en nodosEn primer lugar, necesitará saber qué es la agrupación, cómo se usa en la industria y qué tipo de ventajas y inconvenientes tiene, etc.
Que es la agrupación
Agrupación está estableciendo conectividad entre dos o más servidores para que funcione como uno. La agrupación es una técnica muy popular entre los ingenieros de SYS que pueden agrupar los servidores como un sistema de conmutación por error, un sistema de balance de carga o una unidad de procesamiento paralelo.
Por esta serie de guía, espero guiarte para crear un clúster de Linux con dos nodos en Sombrero rojo/Cento Para un escenario de conmutación por error.
Dado que ahora tiene una idea básica de qué es la agrupación, descubramos qué significa cuando se trata de la agrupación de conmutación por error. Un clúster de conmutación por error es un conjunto de servidores que trabaja en conjunto para mantener la alta disponibilidad de aplicaciones y servicios.
Para un ejemplo, si un servidor falla en algún momento, otro nodo (servidor) se hará cargo de la carga y no le da a un usuario final a ninguna experiencia de tiempo de inactividad. Para este tipo de escenario, necesitamos al menos 2 o 3 servidores para hacer las configuraciones adecuadas.
Prefiero que usemos 3 servidores; Un servidor como el servidor Red Hat Cluster y otros como nodos (servidores de back -end). Veamos el siguiente diagrama para una mejor comprensión.
Servidor de clúster: 172.dieciséis.1.250 Nombre de host: machecería.prueba.neto nodo01: 172.dieciséis.1.222 Nombre de host: ND01Server.prueba.neto nodo02: 172.dieciséis.1.223 Nombre de host: servidor nd02s.prueba.neto
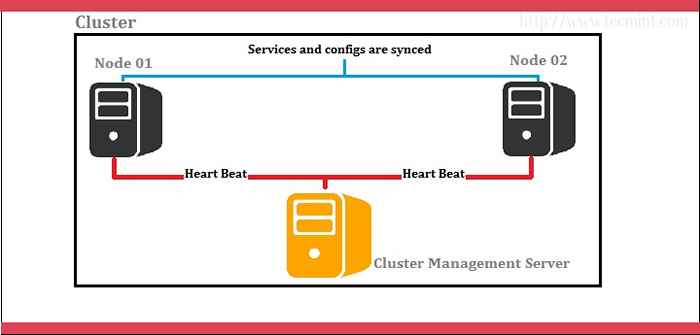 Diagrama de agrupación
Diagrama de agrupación En el escenario anterior, la administración de clúster lo realiza un servidor separado y maneja dos nodos como se muestra en el diagrama. El servidor de administración de clúster envía constantemente las señales del corazón a ambos nodos para verificar si alguien está fallando. Si alguien ha fallado, el otro nodo se hace cargo de la carga.
Ventajas de los servidores de agrupación
- Los servidores de agrupación son completamente una solución escalable. Puede agregar recursos al clúster después.
- Si un servidor en el clúster necesita algún mantenimiento, puede hacerlo deteniéndolo mientras se entrega la carga a otros servidores.
- Entre las opciones de alta disponibilidad, la agrupación ocupa un lugar especial ya que es confiable y fácil de configurar. En el caso de que un servidor tenga problemas para proporcionar los servicios además, otros servidores en el clúster pueden tomar la carga.
Desventajas de los servidores de agrupación
- El costo es alto. Dado que el clúster necesita buen hardware y un diseño, será costoso en comparación con un diseño de administración de servidores no agrupado. No ser rentable es una desventaja principal de este diseño en particular.
- Dado que la agrupación necesita más servidores y hardware para establecer uno, el monitoreo y el mantenimiento es difícil. Por lo tanto, aumente la infraestructura.
Ahora veamos qué tipo de paquetes/instalaciones necesitamos para configurar esta configuración correctamente. Los siguientes paquetes/rpms se pueden descargar por rpmfind.neto.
- RICCI (RICCI-0.dieciséis.2-75.El6.x86_64.RPM)
- Luci (Luci-0.26.0-63.El6.cento.x86_64.RPM)
- Mod_cluster (ModCluster-0.dieciséis.2-29.El6.x86_64.RPM)
- CCS (CCS-0.dieciséis.2-75.EL6_6.2.x86_64.RPM)
- CMAN (CMAN-3.0.12.1-68.El6.x86_64.RPM)
- Clusterlib (clusterlib-3.0.12.1-68.El6.x86_64.RPM)
Veamos qué hace cada instalación por nosotros y sus significados.
- Ricci es un demonio que se usa para la administración y configuraciones de clúster. Distribuye/despacha que reciben mensajes a los nodos configurados.
- Luci es un servidor que se ejecuta en el servidor de administración de clúster y se comunica con otros nodos múltiples. Proporciona una interfaz web para facilitar las cosas.
- Mod_cluster es una utilidad de equilibrio de carga basada en servicios HTTPD y aquí se utiliza para comunicar las solicitudes entrantes con los nodos subyacentes.
- CCS se usa para crear y modificar la configuración del clúster en nodos remotos a través de RICCI. También se usa para comenzar y detener los servicios de clúster.
- CMAN es una de las principales utilidades que no sean Ricci y Luci para esta configuración en particular, ya que esto actúa como gerente de clúster. En realidad, CMAN representa el gerente de clúster. Es un complemento de alta disponibilidad para Redhat que se distribuye entre los nodos en el clúster.
Lea el artículo, comprenda el escenario al que vamos a crear la solución y configure los requisitos previos para la implementación. Reunámonos con la Parte 2, en nuestro próximo artículo, donde aprendemos a instalar y crear el clúster para el escenario dado.
Referencias:
- documentación de Ch-CMan
- Documentación del clúster mod
Mantener conectado con Tecmenta para Handy y Last How to's. Estén atentos para el Parte 02 (Servidores de Linux se agrupa con 2 nodos para un escenario de conmutación por error en Redhat/CentOS - Crear el clúster) Pronto.
- « Actualizar Ubuntu 14.04 (Tahr de confianza) a Ubuntu 14.10 (Unicornio Utópico)
- Ubuntu 14.10 Nombre de código Utopic Unicorn Guía de instalación de escritorio con capturas de pantalla »