

Shell Linux Eliminar líneas duplicadas del archivo
- 3547
- 345
- Eduardo Tapia
Bash es uno de los conchas más populares y es utilizado por muchos usuarios de Linux. Una de las mejores cosas que puede hacer con Bash se elimina las líneas duplicadas de los archivos. Es una excelente manera de desaprobar un archivo y hacer que se vea más limpio y más organizado. Esto se puede hacer con un comando simple en el shell bash.
Todo lo que tienes que hacer es escribir el comando "Sort -u" seguido del nombre del archivo. Esto tomará el archivo y ordenará el contenido, luego use el comando "Uniq" Para eliminar todos los duplicados. Es una forma fácil y eficiente de eliminar las líneas duplicadas de sus archivos. Si eres un usuario de Linux, esta es una gran herramienta para tener en tu arsenal. Entonces, la próxima vez que necesite limpiar un archivo, pruebe este comando bash y vea cómo funciona para usted!
Eliminar líneas duplicadas del archivo
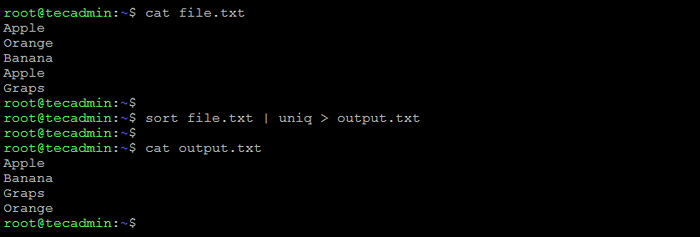
Para eliminar las líneas duplicadas de un archivo en Bash, puede usar los comandos Sort y UNIQ.
Aquí hay un ejemplo de cómo hacerlo:
Archivo de clasificación.txt | UNIQ> Salida.TXT Esto ordenará las líneas en archivo.TXT, eliminar los duplicados y guarde el resultado en un nuevo archivo llamado salida.TXT.
Eliminar líneas duplicadas del archivoTambién puedes usar el -u opción del comando de clasificación para lograr el mismo resultado:
Ordenar el archivo.txt> salida.TXT Si desea eliminar los duplicados en el lugar, sin crear un archivo nuevo, puede usar el comando Tee para redirigir la salida nuevamente al archivo original:
Archivo de clasificación.txt | Uniq | archivo de tee.TXT[O]Ordenar el archivo.txt | archivo de tee.TXT
Tenga en cuenta que estos comandos solo eliminarán los duplicados si las líneas son exactamente las mismas. Si desea ignorar el espacio en blanco principal o inaugural, o las diferencias de casos, puede usar el -i, -b, y -F opciones, respectivamente. Por ejemplo:
Ordenar -f -U archivo.txt> salida.TXT Esto eliminará los duplicados, ignorando las diferencias de casos.
sort -f -b -u archivo.txt> salida.TXT Esto eliminará los duplicados, ignorando las diferencias de casos y el espacio en blanco liderado/trasero.
- « Cómo abrir puerto para una red específica en firewalld
- Configuración del proxy inverso NGINX frente a Apache »