

Cómo instalar chispa en rhel 8
- 1880
- 208
- Sra. María Teresa Rentería
Apache Spark es un sistema informático distribuido. Consiste en un maestro y uno o más esclavos, donde el maestro distribuye el trabajo entre los esclavos, dando así la capacidad de usar nuestras muchas computadoras para trabajar en una tarea. Uno podría adivinar que esta es una herramienta poderosa donde las tareas necesitan cálculos grandes para completar, pero se pueden dividir en trozos de pasos más pequeños que pueden empujar a los esclavos para trabajar. Una vez que nuestro clúster está en funcionamiento, podemos escribir programas para ejecutarlo en Python, Java y Scala.
En este tutorial, trabajaremos en una sola máquina que ejecuta Red Hat Enterprise Linux 8, e instalaremos el Spark Master and Slave en la misma máquina, pero tenga en cuenta que los pasos que describen la configuración de esclavos se pueden aplicar a cualquier cantidad de computadoras, creando así un clúster real que puede procesar cargas de trabajo pesadas. También agregaremos los archivos de unidad necesarios para la administración y ejecutaremos un ejemplo simple contra el clúster enviado con el paquete distribuido para garantizar que nuestro sistema esté operativo.
En este tutorial aprenderás:
- Cómo instalar Spark Master y Slave
- Cómo agregar archivos de la unidad Systemd
- Cómo verificar una conexión exitosa del esclavo maestro
- Cómo ejecutar un trabajo de ejemplo simple en el clúster
Spark Shell con Pyspark. Requisitos y convenciones de software utilizados
| Categoría | Requisitos, convenciones o versión de software utilizada |
|---|---|
| Sistema | Red Hat Enterprise Linux 8 |
| Software | Apache Spark 2.4.0 |
| Otro | Acceso privilegiado a su sistema Linux como root o a través del sudo dominio. |
| Convenciones | # - requiere que los comandos de Linux dados se ejecuten con privilegios raíz directamente como un usuario raíz o mediante el uso de sudo dominiops - Requiere que los comandos de Linux dados se ejecuten como un usuario regular no privilegiado |
Cómo instalar chispa en redhat 8 instrucciones paso a paso
Apache Spark se ejecuta en JVM (Java Virtual Machine), por lo que se requiere una instalación de Java 8 en funcionamiento para que las aplicaciones se ejecuten. Aparte de eso, hay múltiples conchas enviadas dentro del paquete, uno de ellos es pyspark, un caparazón a base de pitón. Para trabajar con eso, también necesitará Python 2 instalado y configurado.
- Para obtener la URL del último paquete de Spark, necesitamos visitar el sitio de descargas de Spark. Necesitamos elegir el espejo más cercano a nuestra ubicación y copiar la URL proporcionada por el sitio de descarga. Esto también significa que su URL puede ser diferente del siguiente ejemplo. Instalaremos el paquete debajo
/optar/, Entonces entramos en el directorio comoraíz:# CD /OPT
Y alimente la URL acumulada para
wgetPara obtener el paquete:# wget https: // www-eu.apache.org/Dist/Spark/Spark-2.4.0/chispa-2.4.0-bin-hadoop2.7.tgz
- Desempacaremos el tarball:
# tar -xvf spark -2.4.0-bin-hadoop2.7.tgz
- Y cree un enlace simbólico para que nuestros caminos sean más fáciles de recordar en los próximos pasos:
# ln -s /opt /spark -2.4.0-bin-hadoop2.7 /OPT /Spark
- Creamos un usuario no privilegiado que ejecutará tanto aplicaciones, maestro como esclavo:
# UserAdd Spark
Y establecerlo como propietario de todo
/OPT/Sparkdirectorio, recursivamente:# Chown -r Spark: Spark /Opt /Spark*
- Creamos un
systemarchivo de la unidad/etc/systemd/system/spark-master.servicioPara el servicio maestro con el siguiente contenido:
Copiar[Unidad] Descripción = Apache Spark Master After = Network.Target [Service] Type = Forking User = Spark Group = Spark Exectart =/Opt/Spark/Sbin/Start-Master.SH Execstop =/Opt/Spark/Sbin/Stop-Master.sh [install] WantedBy = Multiuser.objetivoY también uno para el servicio de esclavos que será
/etc/systemd/system/spark-slave.servicio.servicioCon el siguiente contenido:
Copiar[Unidad] Descripción = Apache Spark Slave After = Network.Target [Service] Type = Forking User = Spark Group = Spark Execstart =/Opt/Spark/Sbin/Start-Slave.sh chispa: // rhel8lab.LinuxConfig.org: 7077 execstop =/opt/spark/sbin/stop-slave.sh [install] WantedBy = Multiuser.objetivoTenga en cuenta la URL de chispa resaltada. Esto se construye con
chispa: //: 7077, En este caso, la máquina de laboratorio que ejecutará el maestro tiene el nombre de hostrhel8lab.LinuxConfig.organizar. El nombre de tu maestro será diferente. Todos los esclavos deben poder resolver este nombre de host y llegar al maestro en el puerto especificado, que es puerto7077por defecto. - Con los archivos de servicio en su lugar, necesitamos preguntar
systemPara volver a leerlos:# SystemCTL-Daemon-Re-Reloting
- Podemos comenzar nuestro Spark Master con
system:# SystemCTL Start Spark-Master.servicio
- Para verificar que nuestro maestro se ejecute y funcione, podemos usar el estado de Systemd:
# SystemCTL Status Spark-Master.Servicio de chispas.Servicio - Apache Spark Master cargado: cargado (/etc/systemd/system/spark -master.servicio; desactivado; Vendor Preset: Discapaced) Activo: Activo (Running) desde viernes 2019-01-11 16:30:03 CET; Proceso de hace 53 minutos: 3308 Execstop =/Opt/Spark/Sbin/Stop-Master.SH (CODE = EXITADO, ESTADO = 0/STARCE) Proceso: 3339 ExecStart =/Opt/Spark/Sbin/Start-Master.SH (Código = Exitido, Estado = 0/Success) Principal PID: 3359 (Java) Tareas: 27 (Límite: 12544) Memoria: 219.3M CGROUP: /SISTEMA.portaobjetos/maestro.Servicio 3359/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181.B13-9.El8.x86_64/jre/bin/java -cp/opt/spark/conf/:/opt/spark/jars/* -xmx1g orgg.apache.Chispa - chispear.desplegar.maestro.Maestro -Host […] 11 de enero 16:30:00 Rhel8lab.LinuxConfig.org Systemd [1]: Iniciar Apache Spark Master ... 11 de enero 16:30:00 RHEL8LAB.LinuxConfig.org-maestro de inicio.SH [3339]: Comenzar orgg.apache.Chispa - chispear.desplegar.maestro.Maestro, Registro a/opt/Spark/Logs/Spark-Spark-ORG.apache.Chispa - chispear.desplegar.maestro.Maestro-1 […]
La última línea también indica el archivo de registro principal del maestro, que está en el
registroDirectorio bajo el directorio de la base de Spark,/OPT/Sparken nuestro caso. Al investigar este archivo, deberíamos ver una línea al final similar al siguiente ejemplo:2019-01-11 14:45:28 Información Maestro: 54-He sido elegido líder! Nuevo estado: vivo
También debemos encontrar una línea que nos diga dónde está escuchando la interfaz maestra:
2019-01-11 16:30:03 Información Utiliza: 54-Servicio iniciado con éxito 'Masterui' en el puerto 8080
Si señalamos un navegador al puerto de la máquina host
8080, Deberíamos ver la página de estado del maestro, sin trabajadores adjuntos en este momento.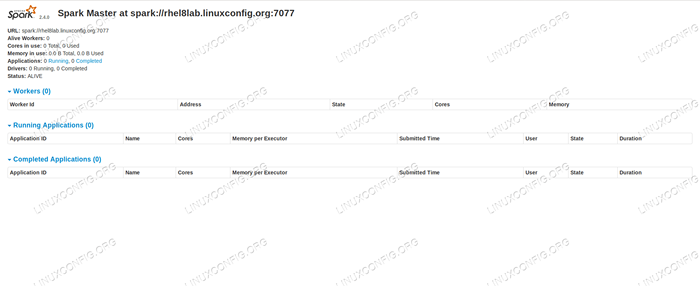 Spark Master Status Página sin trabajadores adjuntos.
Spark Master Status Página sin trabajadores adjuntos. Tenga en cuenta la línea de URL en la página de estado de Spark Master. Esta es la misma URL que debemos usar para cada archivo de unidad de esclavo que creamos
Paso 5.
Si recibimos un mensaje de error de "conexión rechazada" en el navegador, probablemente necesitemos abrir el puerto en el firewall:# firewall-cmd --zone = public --add-port = 8080/tcp-Permanent Success # Firewall-CMD-Re-Reload Success
- Nuestro maestro se está ejecutando, le conectaremos un esclavo. Comenzamos el servicio de esclavos:
# SystemCTL Start Spark-Slave.servicio
- Podemos verificar que nuestro esclavo se esté ejecutando con Systemd:
# SystemCTL Status Spark-Slave.Servicio Spark-Slave.Servicio - Apache Spark Slave cargado: cargado (/etc/systemd/system/spark -slave.servicio; desactivado; Vendor Preset: Discapaced) Activo: Activo (Running) desde viernes 2019-01-11 16:31:41 CET; Proceso de hace 3 minutos: 3515 Execstop =/Opt/Spark/Sbin/Stop-Slave.SH (CODE = EXITADO, STATUS = 0/Success) Proceso: 3537 ExecStart =/Opt/Spark/Sbin/Start-Slave.sh chispa: // rhel8lab.LinuxConfig.org: 7077 (código = exitido, estado = 0/éxito) PID principal: 3554 (Java) Tareas: 26 (Límite: 12544) Memoria: 176.1M CGROUP: /SISTEMA.corte/esclavo.Servicio 3554/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181.B13-9.El8.x86_64/jre/bin/java -cp/opt/spark/conf/:/opt/spark/jars/* -xmx1g orgg.apache.Chispa - chispear.desplegar.obrero.Trabajador […] 11 de enero 16:31:39 Rhel8lab.LinuxConfig.Org Systemd [1]: Iniciar esclavo de apache chispa ... 11 de enero 16:31:39 rhel8lab.LinuxConfig.org-esclavo.SH [3537]: Comenzar orgg.apache.Chispa - chispear.desplegar.obrero.Trabajador, registro a/opt/spark/logs/spark-spar […]
Esta salida también proporciona la ruta al archivo de registro del esclavo (o trabajador), que estará en el mismo directorio, con "trabajador" en su nombre. Al verificar este archivo, deberíamos ver algo similar a la siguiente salida:
2019-01-11 14:52:23 Información Trabajador: 54-Conectarse con el Maestro RHEL8LAB.LinuxConfig.org: 7077… 2019-01-11 14:52:23 Información Contextandler: 781-Comenzó O.s.j.s.ServletContexthandler@62059f4a /Metrics/JSON, NULL, disponible,@Spark 2019-01-11 14:52:23 Información TransportClientFactory: 267-Conexión creada con éxito a Rhel8Lab.LinuxConfig.org/10.0.2.15: 7077 después de 58 ms (0 ms gastados en bootstraps) 2019-01-11 14:52:24 Información Trabajador: 54-Registrado con éxito con Master Spark: // Rhel8lab.LinuxConfig.org: 7077
Esto indica que el trabajador está conectado con éxito al maestro. En este mismo archivo de registro encontraremos una línea que nos diga la URL en la que está escuchando el trabajador:
2019-01-11 14:52:23 INFO WORKERWEBUI: 54-Bound Workerwebui a 0.0.0.0, y comenzó en http: // rhel8lab.LinuxConfig.org: 8081
Podemos señalar nuestro navegador a la página de estado del trabajador, donde su maestro se enumera.
 Página de estado del trabajador de chispa, conectado al maestro.
Página de estado del trabajador de chispa, conectado al maestro.
En el archivo de registro del maestro, debería aparecer una línea de verificación:
2019-01-11 14:52:24 Información Maestro: 54-Trabajador de registro 10.0.2.15: 40815 con 2 núcleos, 1024.0 MB RAM
Si recargamos la página de estado del maestro ahora, el trabajador también debe aparecer allí, con un enlace a su página de estado.
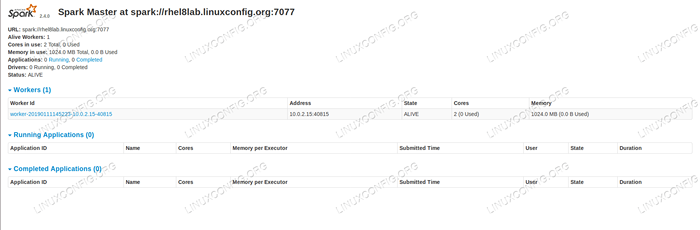 Página de estado de Spark Master con un trabajador adjunto.
Página de estado de Spark Master con un trabajador adjunto. Estas fuentes verifican que nuestro clúster esté conectado y listo para funcionar.
- Para ejecutar una tarea simple en el clúster, ejecutamos uno de los ejemplos enviados con el paquete que descargamos. Considere el siguiente archivo de texto simple
/OPT/Spark/Test.archivo:
Copiarlínea1 word1 word2 word3 line2 word1 line3 word1 word2 word3 word4Ejecutaremos el
el recuento de palabras.pyEjemplo que contará la ocurrencia de cada palabra en el archivo. Podemos usar elChispa - chispearUsuario, noraízSe necesitan privilegios.$/opt/spark/bin/spark-submit/opt/spark/ejemplos/src/main/python/wordcount.py/opt/spark/test.Archivo 2019-01-11 15:56:57 Información SparkContext: 54-Solicitud enviada: PythonwordCount 2019-01-11 15:56:57 Información SecurityManager: 54-Cambiar las ACL a: Spark 2019-01-11 15:56: 57 Info SecurityManager: 54 - Cambiar ACL de modificación a: Spark […]
A medida que se ejecuta la tarea, se proporciona una salida larga. Cerca del final de la salida, se muestra el resultado, el clúster calcula la información necesaria:
2019-01-11 15:57:05 Información Dagscheduler: 54-Trabajo 0 Terminado: recopilar a/opt/spark/ejemplos/src/main/python/wordcount.Py: 40, tomó 1.619928 S línea3: 1 Línea 2: 1 Línea 1: 1 Word4: 1 Word1: 3 Word3: 2 Word2: 2 […]
Con esto hemos visto nuestra chispa de Apache en acción. Se pueden instalar y conectar nodos esclavos adicionales para escalar la potencia informática de nuestro clúster.
Tutoriales de Linux relacionados:
- Cómo crear un clúster de Kubernetes
- Instalación de Oracle Java en Ubuntu 20.04 fossa focal Linux
- Cosas para instalar en Ubuntu 20.04
- Cómo instalar Java en Manjaro Linux
- Linux: instalar Java
- Cómo instalar Kubernetes en Ubuntu 20.04 fossa focal Linux
- Cómo instalar Kubernetes en Ubuntu 22.04 Jellyfish de Jammy ..
- Ubuntu 20.04 Hadoop
- Una introducción a la automatización, herramientas y técnicas de Linux
- Ubuntu 20.04 WordPress con instalación de Apache